










AI is being touted as a transformative technology for the media space, but audio was an early adopter, writes Kevin Hilton.

In many ways the audio business was an early adopter of what could be described as artificial intelligence (AI). Sure, sound engineers like to be able to control and manipulate sounds, sometimes making minute adjustments in level and equalisation according to their ears and experience rather than what a meter or oscilloscope might be telling them. But there some jobs or processes that are time-consuming and dull so anything that can make life easier by taking over more mundane or repetitive tasks has been embraced.
Total recall and Flying Faders became an integral part of music recording in the 1970s, allowing EQ settings and fader positions to be loaded into a computer attached to the mixing desk and called up at a later time when required. Less flashy and obvious is the work of the ubiquitous compressor, a unit that featured in every studio rack and now every digital audio workstation as a plug-in. It is used in transmission to control peak volumes and in music or broadcast is able to limit the dynamic range of a vocal or instrument.
“Controlling dynamic range and the use of compressors could be a broadcast definition of AI because it is data driven,” comments Christopher Hicks, director of engineering at CEDAR Audio. “It removes the need for a human brain. Anything that is automated can be described as AI.” While the term AI has solid scientific and academic foundations, it has also become something of a nebulous, catch-all buzz phrase, which was not helped by the Steven Spielberg film of the same name.
“We prefer the term machine learning because it has connotations of being able to look at the data that has been extracted directly” Christopher Hicks, CEDAR Audio
There is also some confusion with the associated terms machine learning and digital neural networking (DNN). All three are often used interchangeably but are not synonymous. “AI as a term has been around for decades and in computer science is a big umbrella category,” says Hicks. “We prefer to use the term machine learning because it has connotations of being able to look at the data that has been extracted directly, without working to a prescribed model of what to expect.”
In this way machine learning differs from DNN because it involves loose statistical models as opposed to more rigid parameters. DNN is based on large amounts of training data, derived from specific examples, such as recognising particular types of voices and accents or sounds such as air conditioning or traffic. The drawback is that the program is not effective if presented with something it has not been programmed to recognise.

“DNN is one way of implementing machine learning but it is too rigid,” observes Hicks. CEDAR Audio is a long-standing developer and manufacturer of sound restoration systems. Initially based on hardware devices, its technology is now also available in software form and used widely to clean up and repair location recordings in TV and film post-production, as well as restoring archive material.
CEDAR first employed aspects of machine learning in 2012 when it launched the DNS 8 Live multi-channel dialogue noise suppressor. This is able to remove background noise from speech and although designed for concert halls and conference venues, is also used in broadcast studios, post facilities and for sports anchoring. This was followed by the DNS 2, a portable unit designed for location recording that is able to deal with traffic noise, wind, rain and make allowances for poorly positioned microphones.
- Read more: Unifying AI applications for broadcasters
Gordon Reid, managing director of CEDAR, comments that while the DNS units identify the problem, they also give engineers the flexibility to deal with it as they see fit. He also acknowledges that the company did not at first promote its use of machine learning because the technology was more associated with audio finger printing at the time. This left the way open for other developers to stake their claim to the audio machine learning market, something the US company iZotope has done very successfully.
A lot of noise
During IBC 2018 iZotope, which was already popular among audio post houses for its sound repair software packages, announced a new version of its RX7 noise reduction program featuring machine learning algorithms. This included features for dialogue contouring and the ability to deal with intonation problems and ‘up-speaking’ - the annoying upward inflection at the end of a sentence - without affecting the original speech.
Machine learning was also used to recognise example of clean speech and the types of noise that could affect it. Another tool is Music Rebalance, which is able to identify vocals and specific instruments in a song and then carry out individual gain control of a specific element. It is also possible to isolate or remove the vocal part completely, something that is a popular feature on other programs used in music production.
Lexie Morgan, who worked at iZotope and is now head of marketing at the company’s UK distributor, HHB Communications, says a major benefit of machine learning in audio is to speed up processes or perform tasks people cannot.
“Through machine learning [we are able to] remove parts in pop music or artefacts from speech for ADR” Lexie Morgan, HHB Communications
“It would be hard to go into a track and remove something piece by piece,” she says. “But we are able to go in through machine learning and remove parts in pop music or artefacts from speech for ADR. Rebalance uses DNN to hear what we are hearing and is trained to know what individual things are.”
While RX7 is an editing and clean up system, iZotope’s latest product, Neutron 3, is a mixing and production package primarily for music that is able to suggest track levels and add “polish” and “spectral shaping” to a track. Another leading audio processing plug-in designer is McDSP, which has just released its first product based on machine learning. The SHINE module is part of the 6060 Collection of processors and was produced using an AI computer model to approximate some of McDSP’s frequency curves.
Clean-up
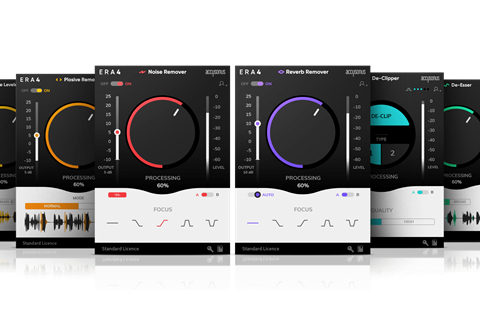
Among other audio processor developers now utilising machine learning are Zynaptiq, Absentia with its DX package and Accusonus. This last company, which has premises in both the US and Greece, has produced its own patented machine learning and AI technologies, which are applied to the ERA range of audio clean up tools. These are aimed variously at audio engineers, filmmakers, video editors and YouTubers.
Research in machine learning and general AI for audio continues apace. Among the institutions involved in this is Fraunhofer IIS, where the Centre for Analytics Data Application has been working on a variety of uses. Among the primary areas is the further development of smart speaker interfaces but it is also engaged in AI-based intelligent signal processing (DSKI). This is intended to develop digital signal processing using AI methods, focusing particularly on source and channel coding.
These are relatively early days for AI/machine learning in audio. As Gordon Reid at CEDAR says, perhaps in 10 to 20 years time developers will look back at what is being done now and view it as people just putting their toes in the water. “Machine learning and neural nets will become better and more efficient,” Reid concludes. “There’s also the possibility that in the future there might be a completely different development path to the one we’re on now.”












No comments yet