Reports

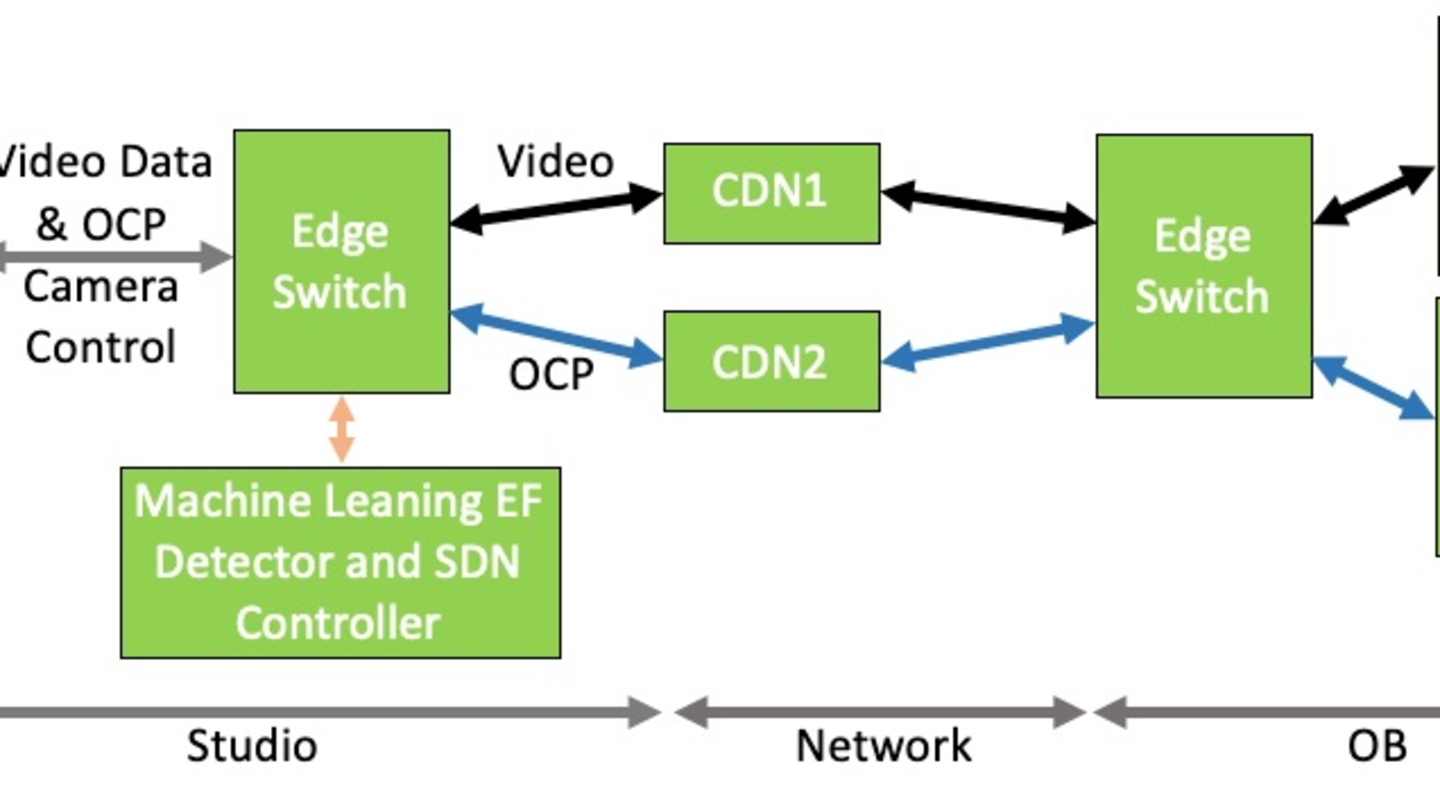
Demonstration of AI-based fancam production for the Kohaku Uta Gassen using 8K cameras and VVERTIGO post-production pipeline
Reports
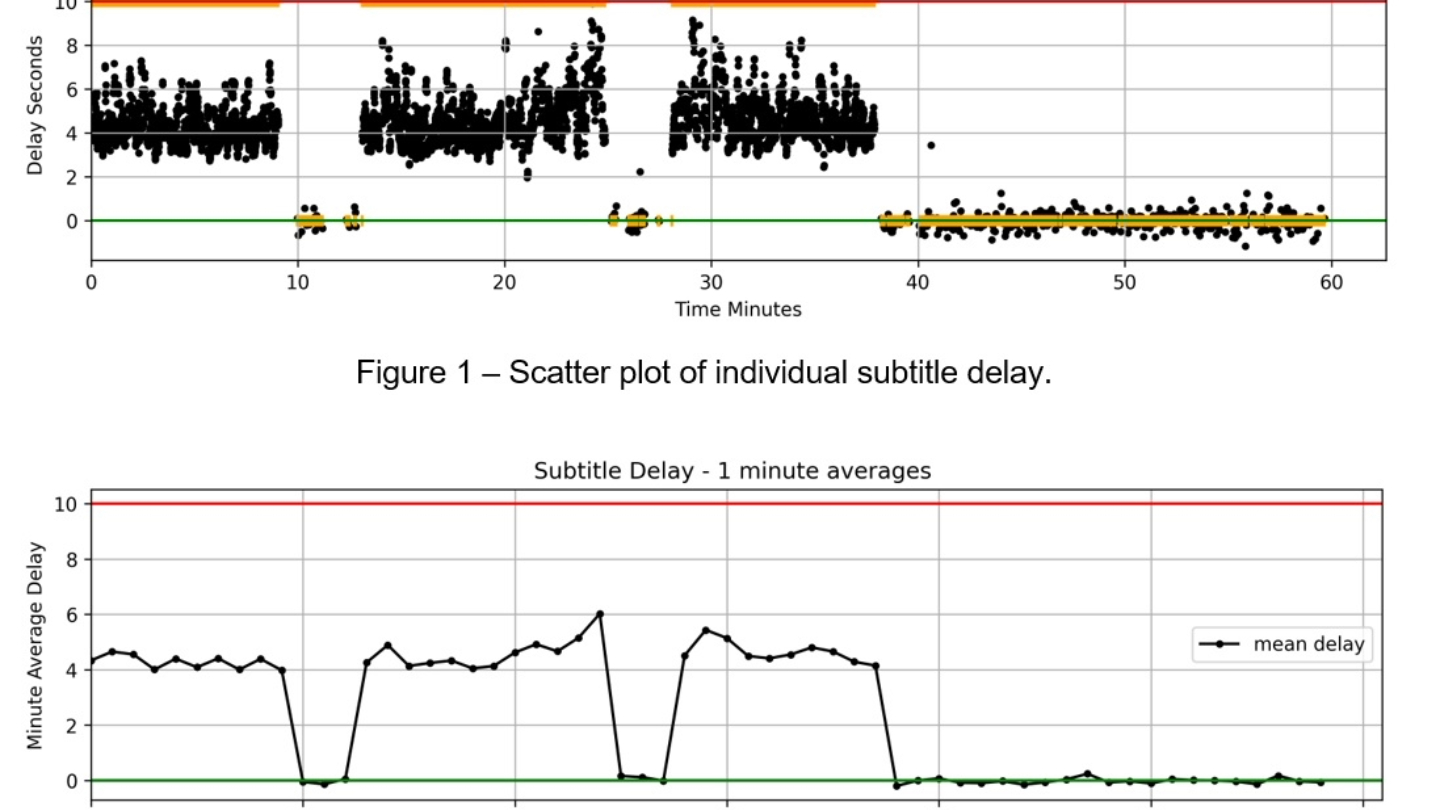
Using generative AI-speech-to-text output to provide automated monitoring of television subtitles
Reports
.jpg)
Reference-free measurement of dialog intelligibility in (post)-production, content analyses, and live broadcast applications



IBC Tech Papers 2024

Reports

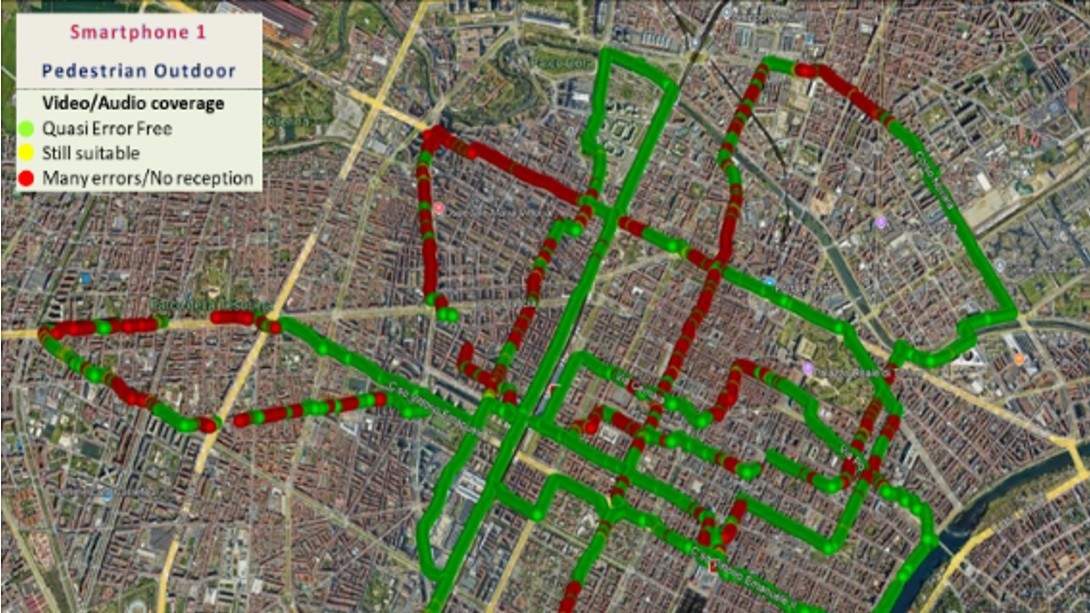
IBC2024 Tech Papers: Project Timbre: How well do mobile networks work for live audio streaming?
Reports

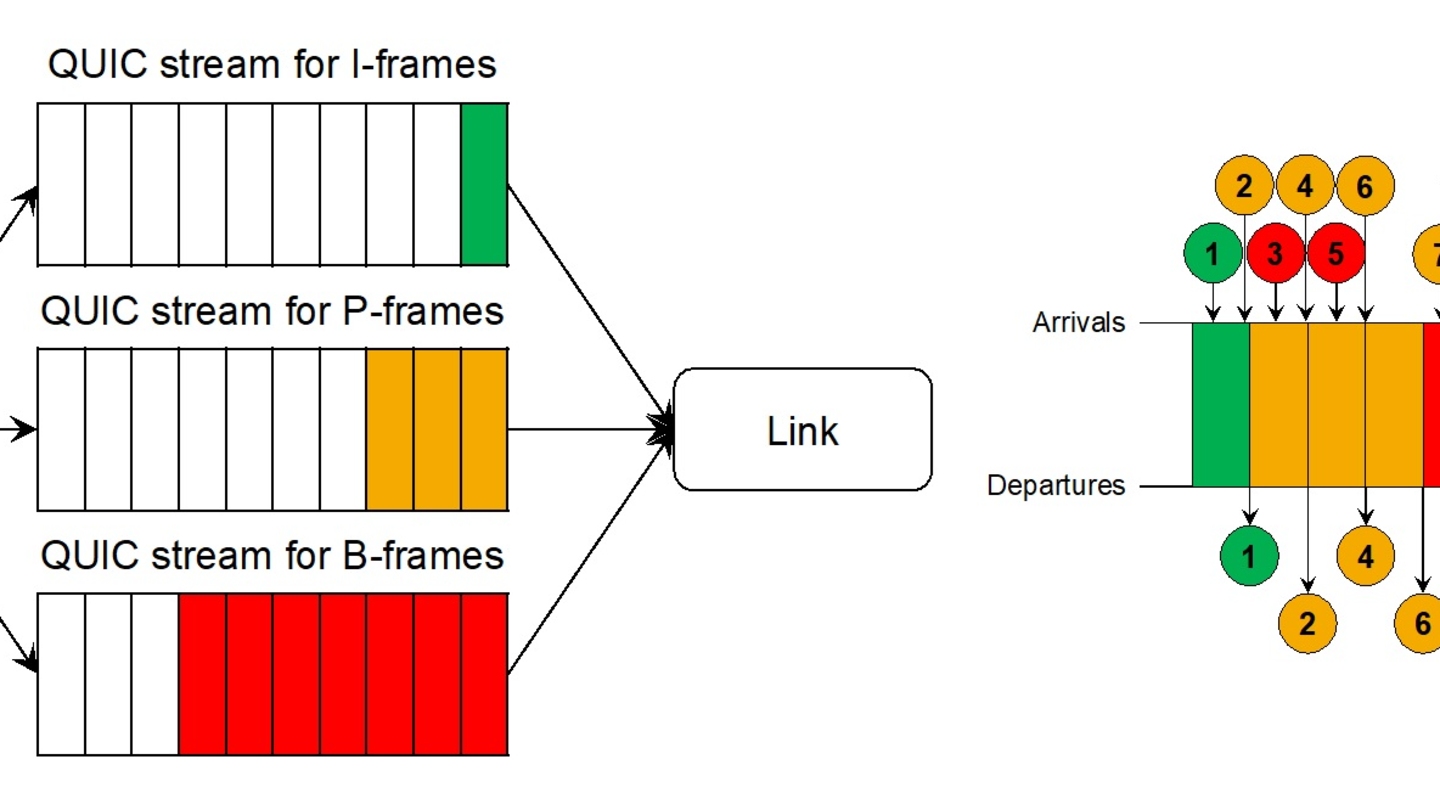
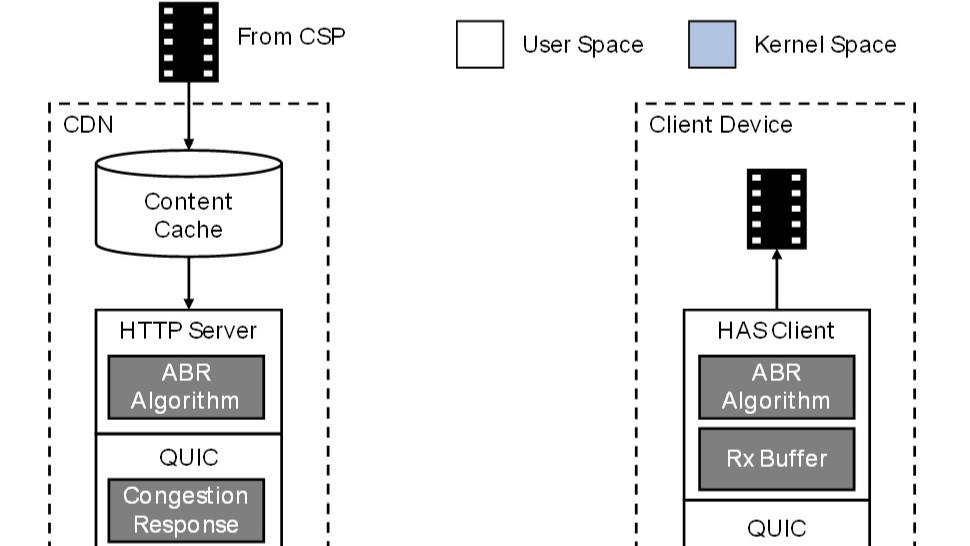
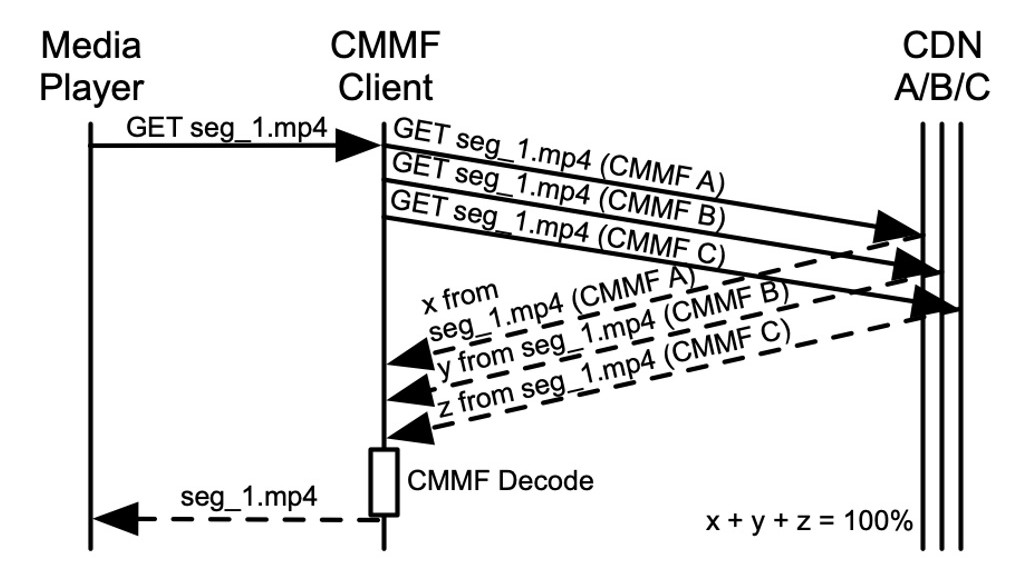
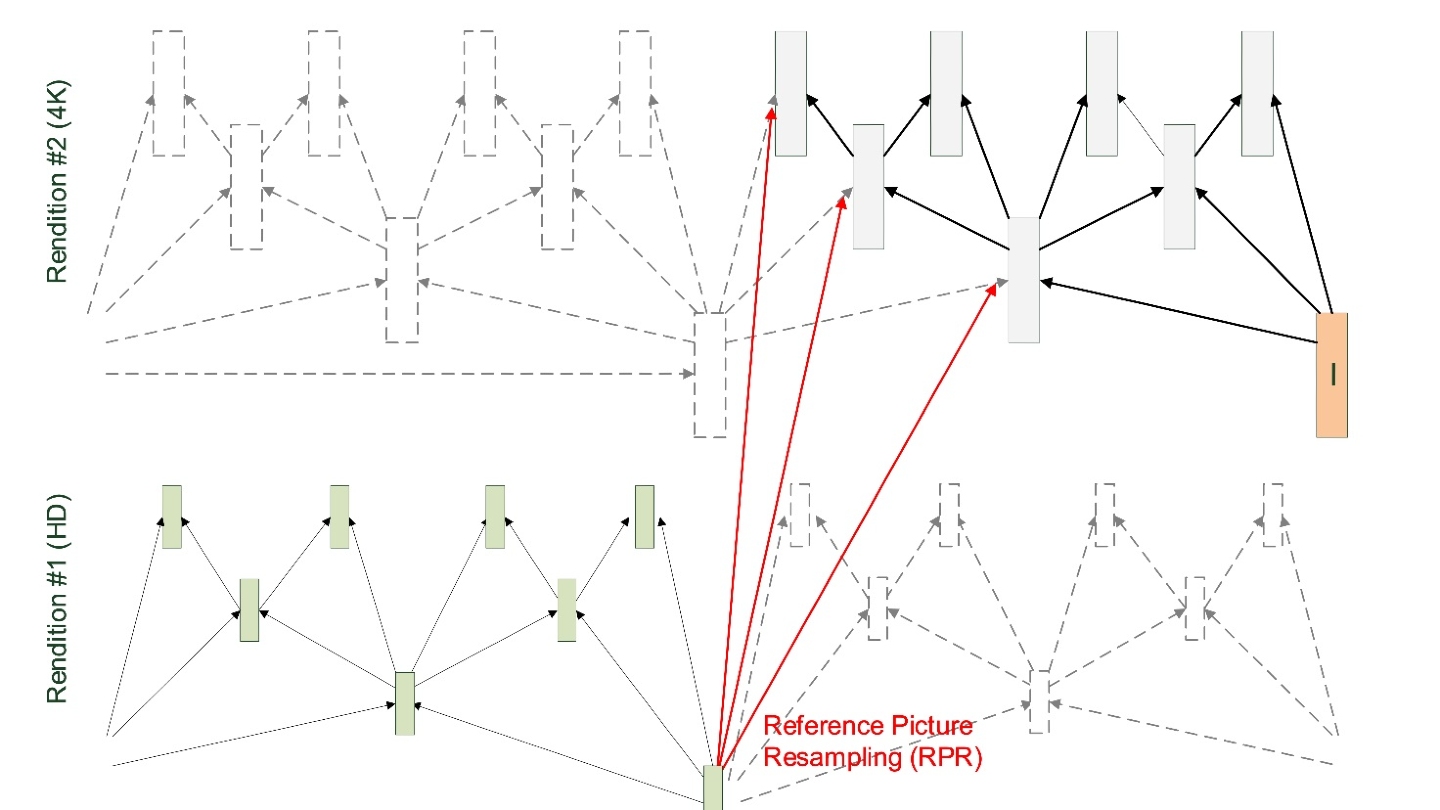
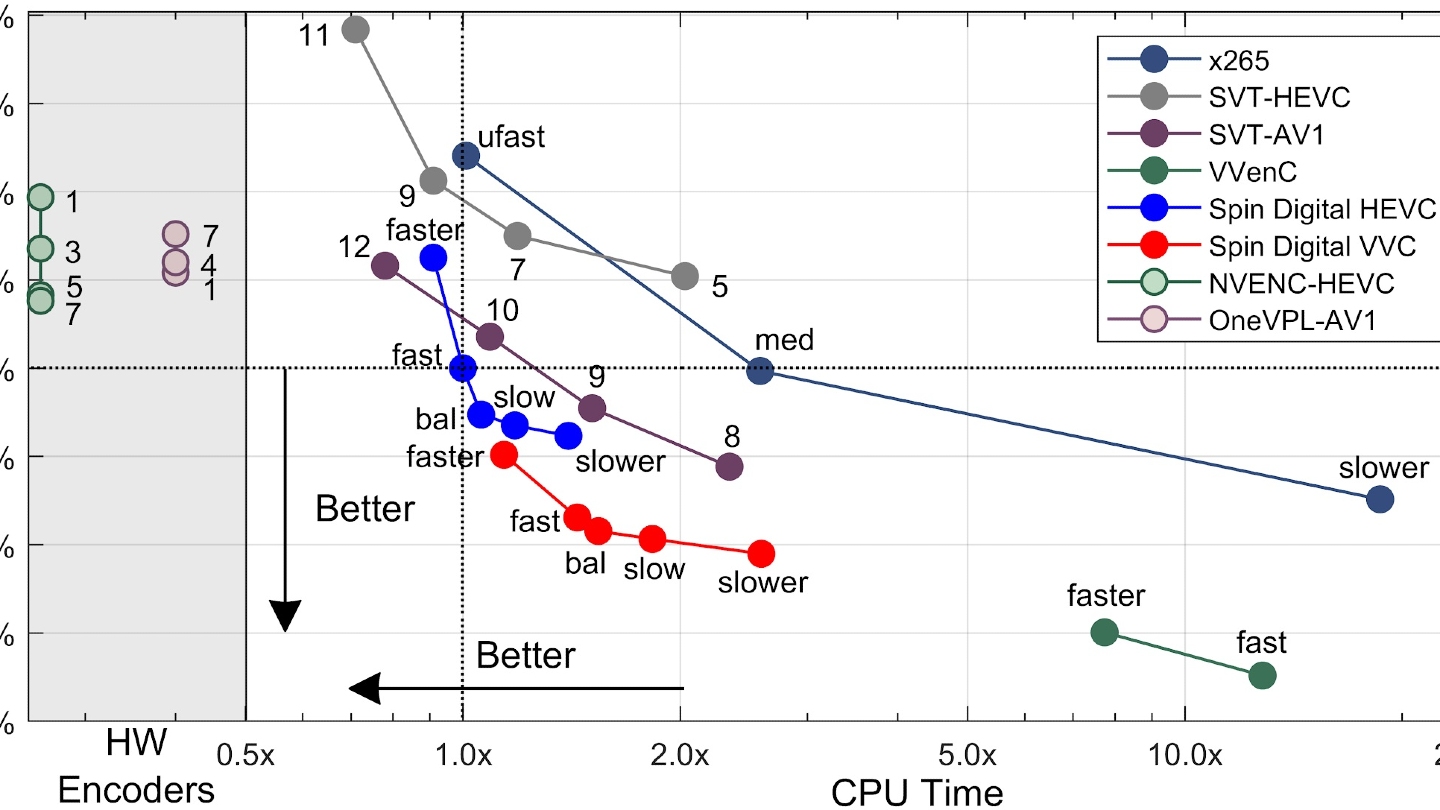
IBC2024 Tech Papers: Novel coding methods for storage bit-cost, transcoding complexity, and transmission efficiency trade-off optimization of multi-profile video delivery system
Reports

IBC2024 Tech Papers: Live Production using the Audio Definition Model at the Eurovision Song Contest 2023

Reports

IBC2024 Tech Papers: Enhancing Film Grain Coding in VVC: Improving Encoding Quality and Efficiency

Reports

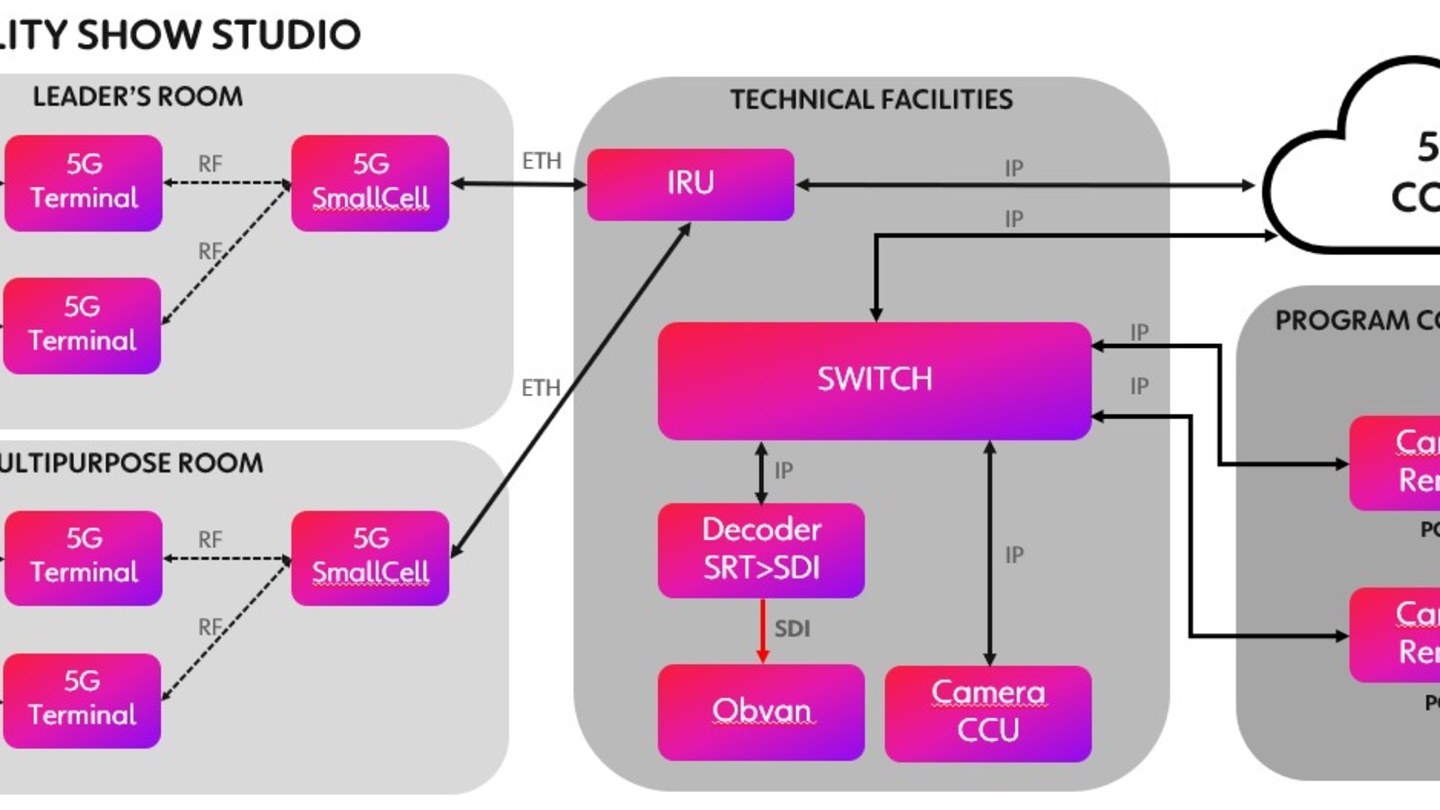
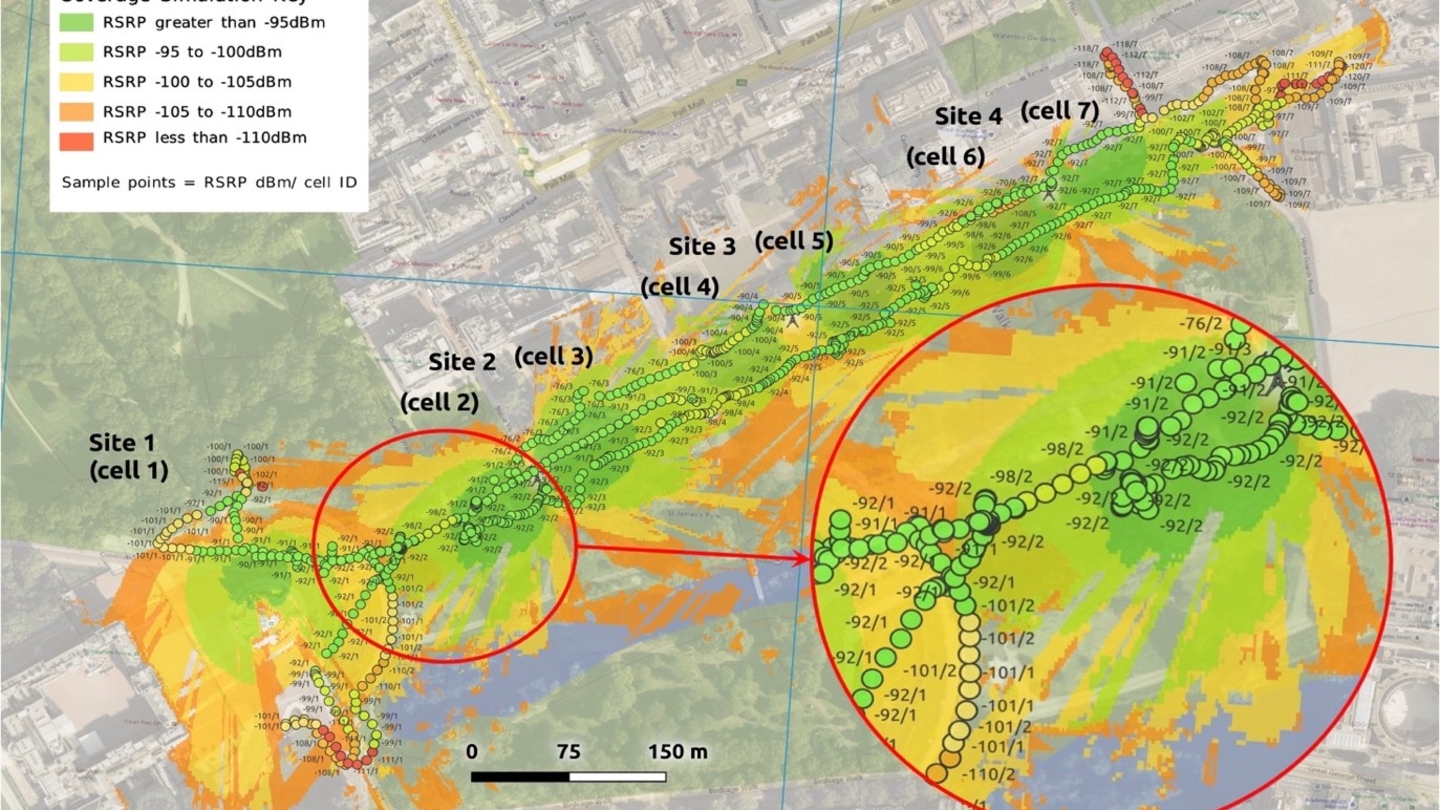
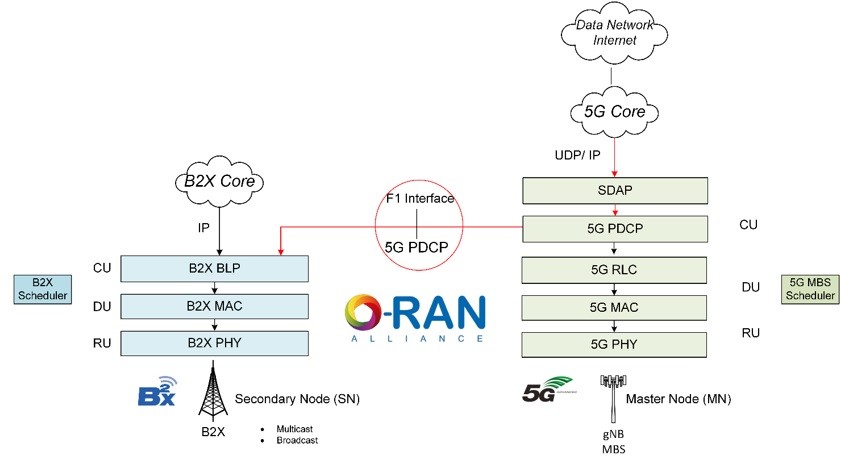
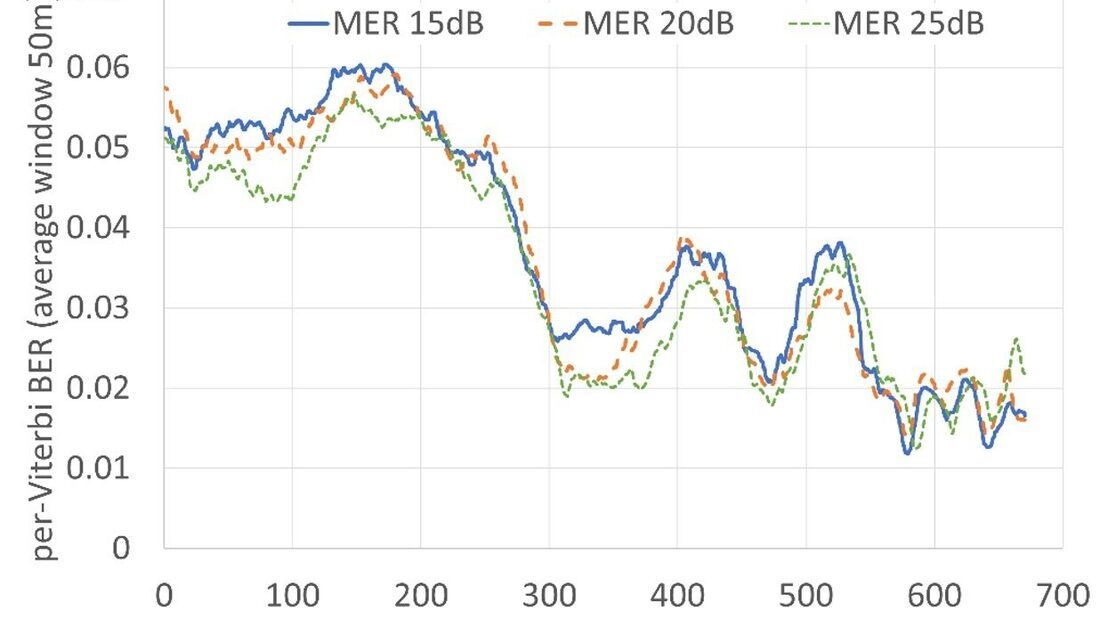
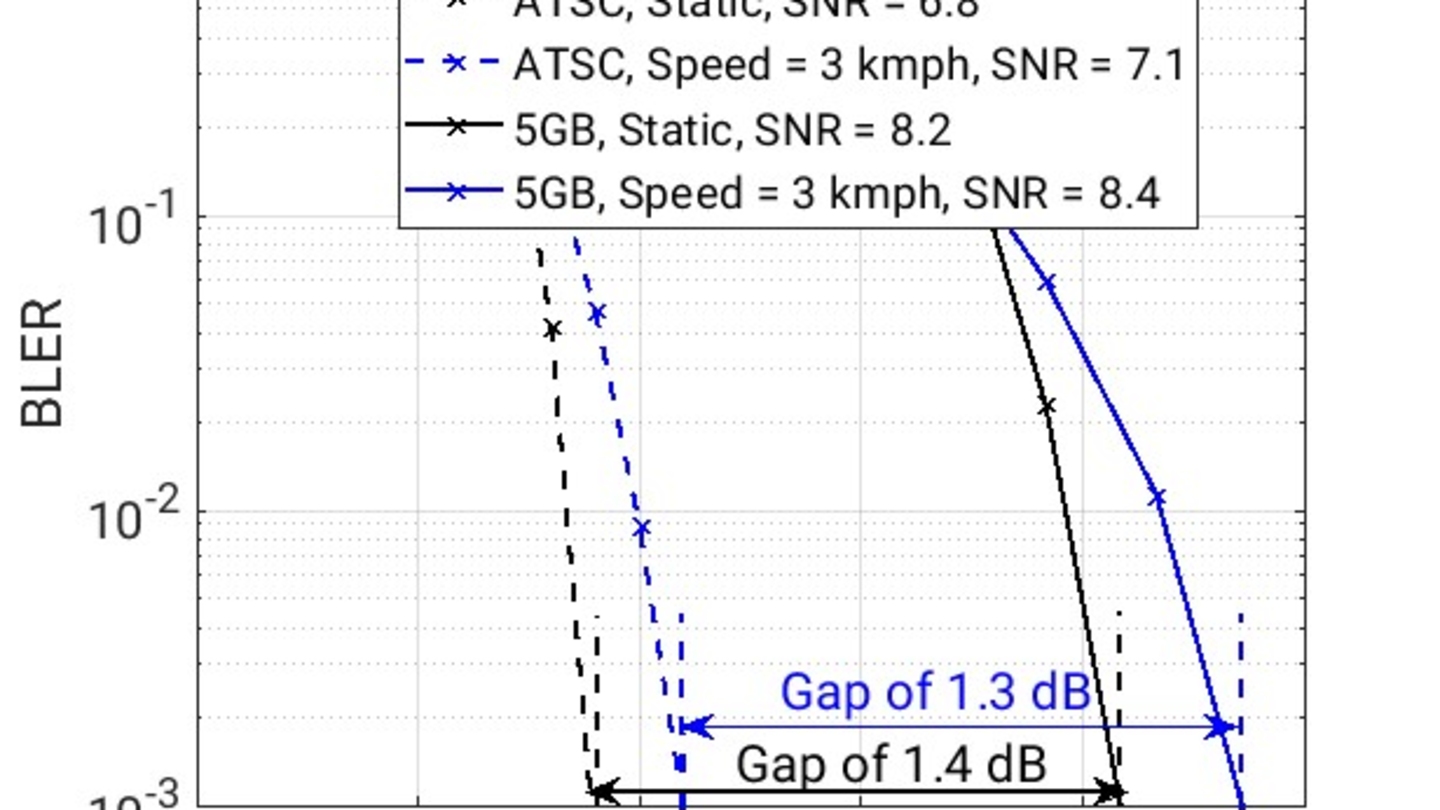
IBC2024 Tech papers: Sub-6GHz 5G Slicing on Public Networks - Field Results, Observations and Roadmap to Ubiquitous 5G Access for Professional Media


Reports

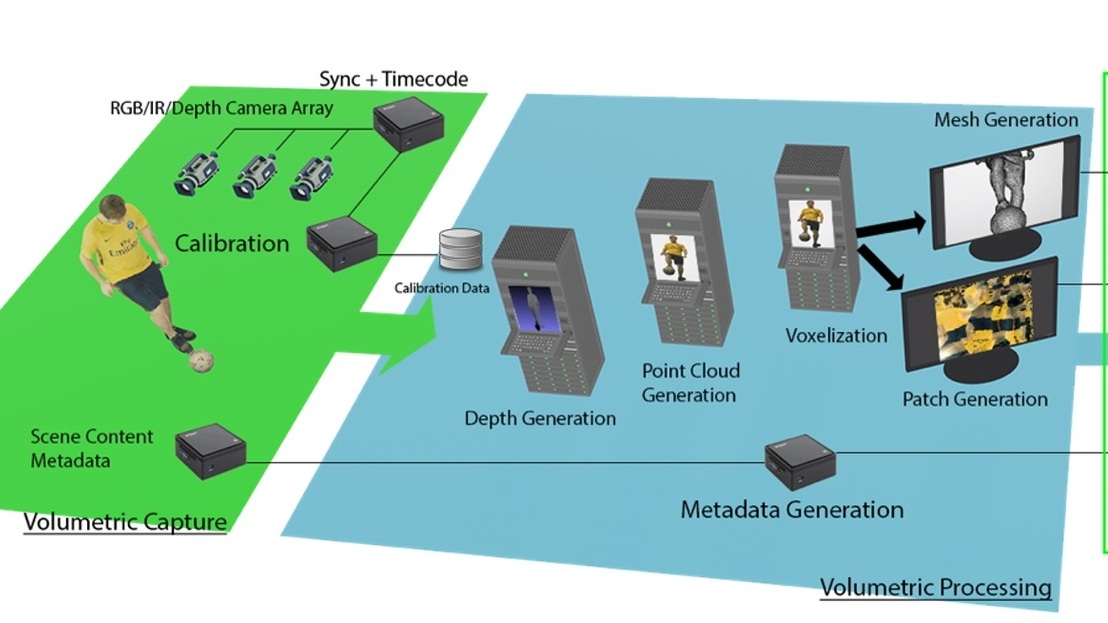
IBC2024 Tech Papers: Advancements in Radiance Field Techniques for Volumetric Video Generation: A Technical Overview
Reports

IBC2024 Tech Papers: Novel Image Sensor with Area-Based Optimisation of Shooting Conditions for Immersive Content Productions






Reports

IBC2024 Tech papers: DVB-I Extensions and 3GPP Service URLs – modernising service announcement and discovery
Reports

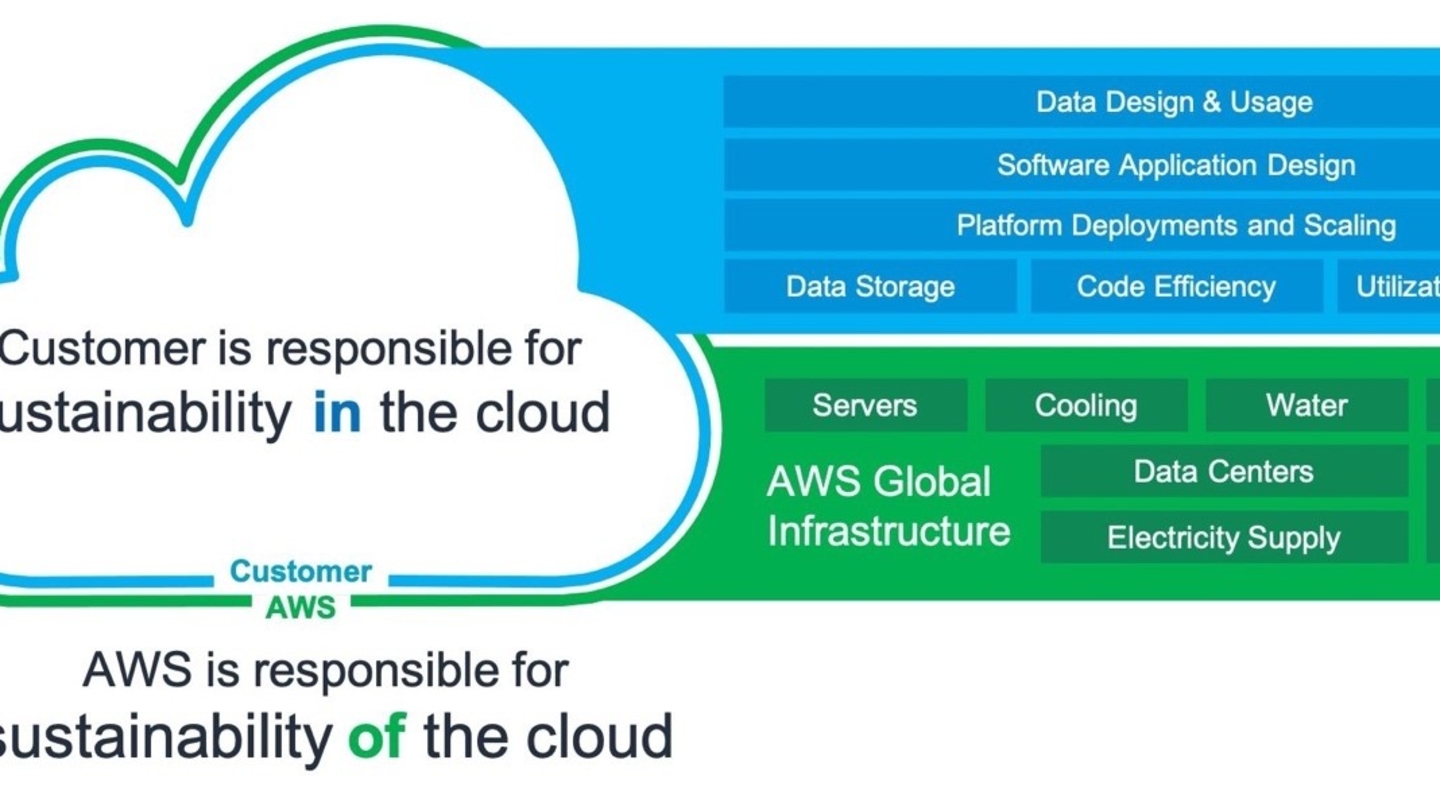
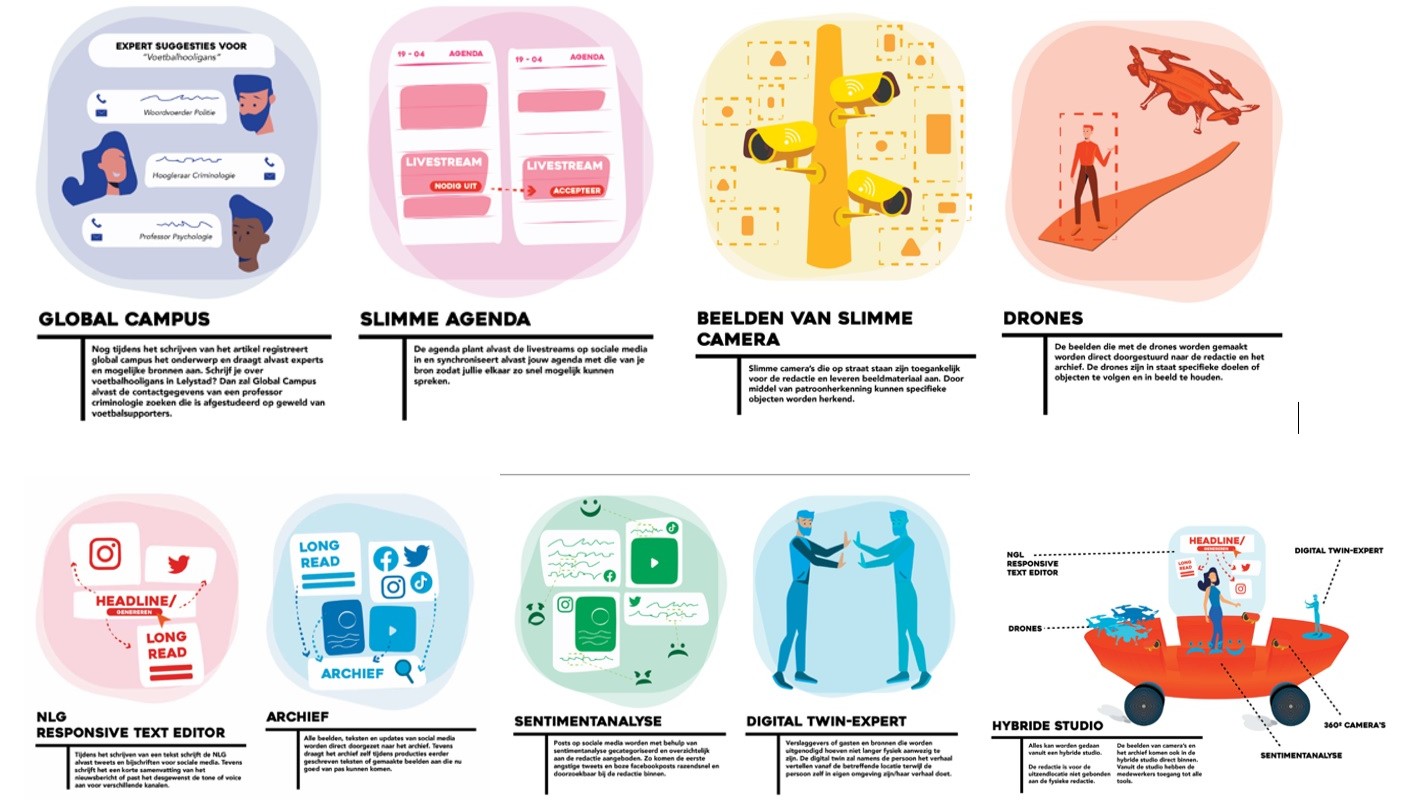
IBC2024 Tech Papers: The Power of Data-Driven Insights: Advancing Ad Targeting With Generative AI

IBC Tech Papers 2023

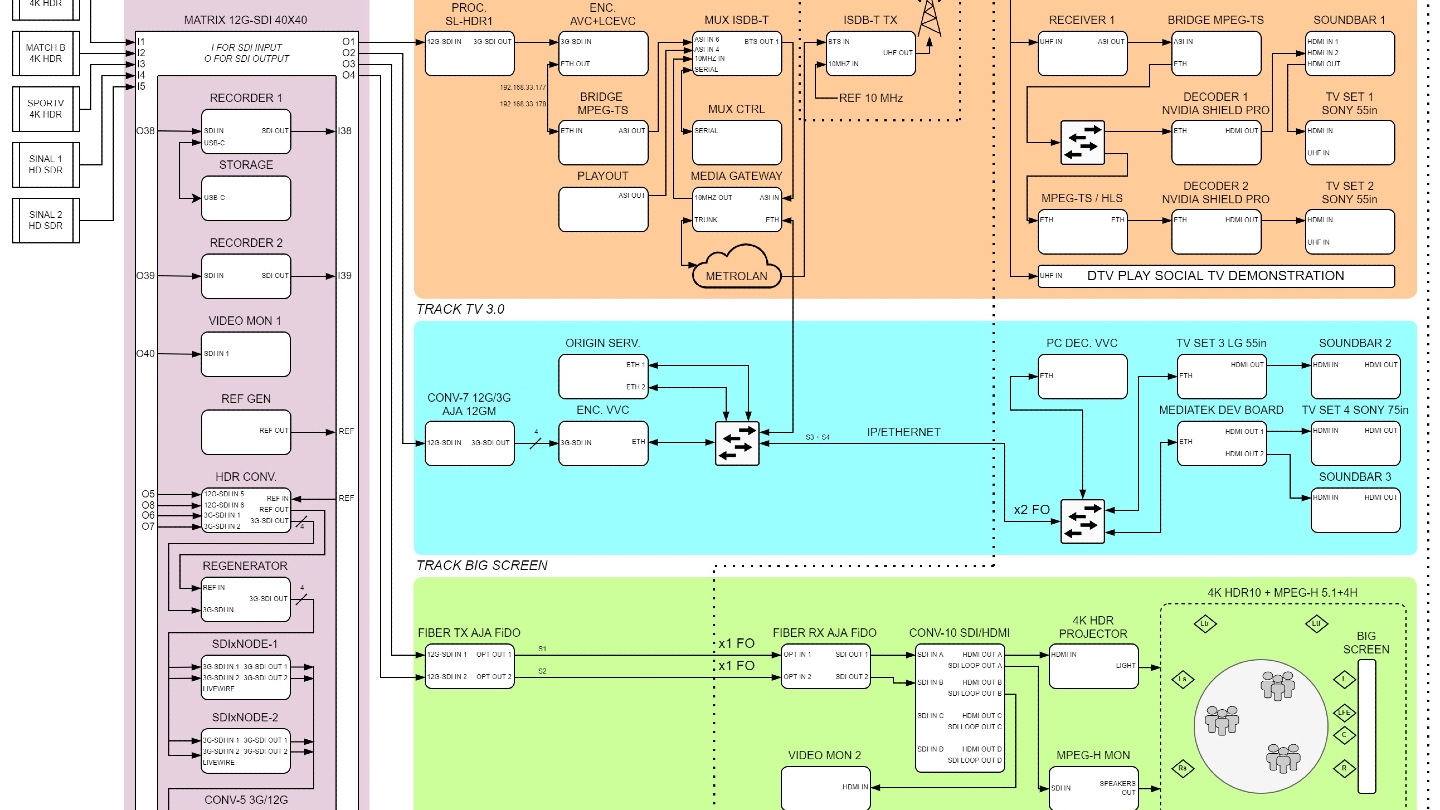
Reports
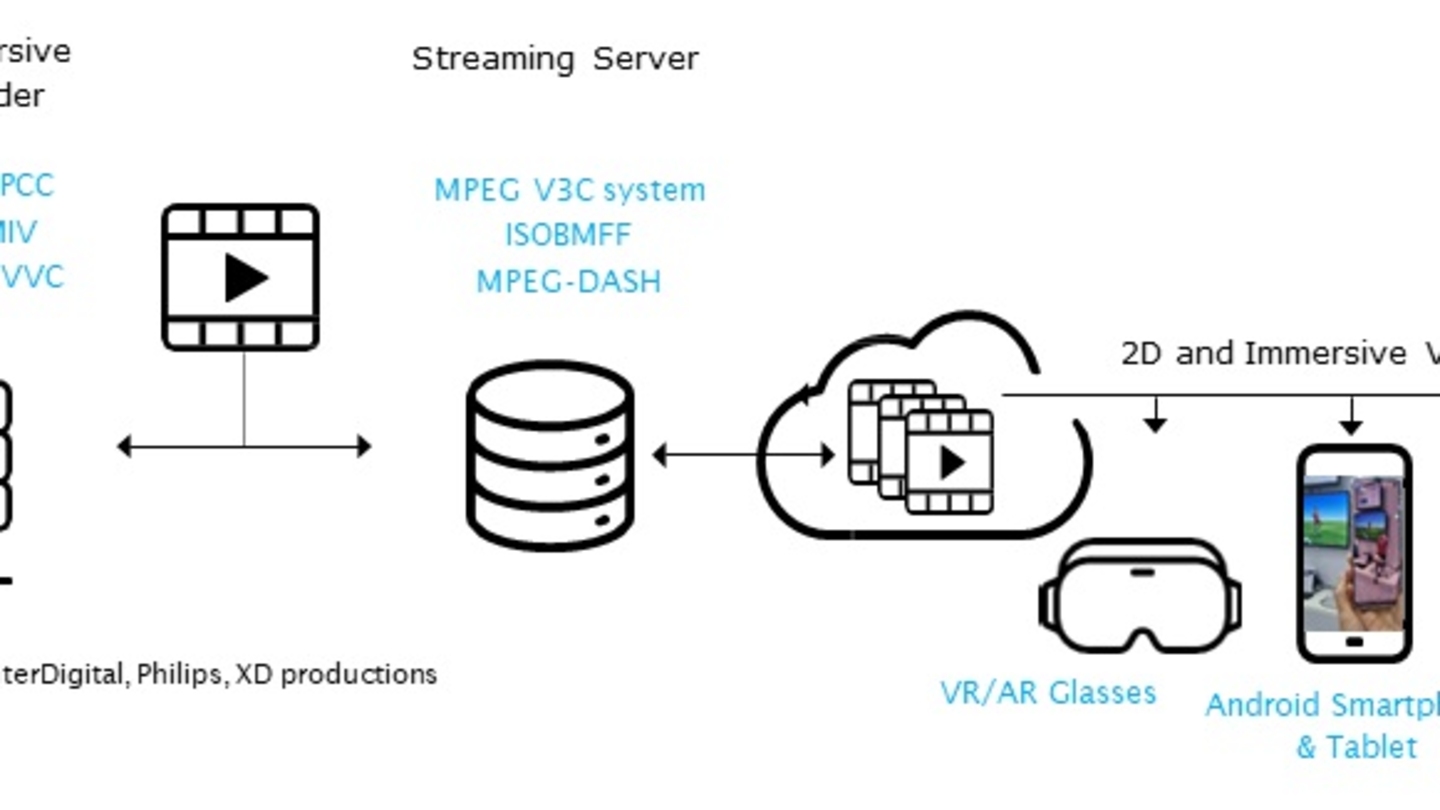
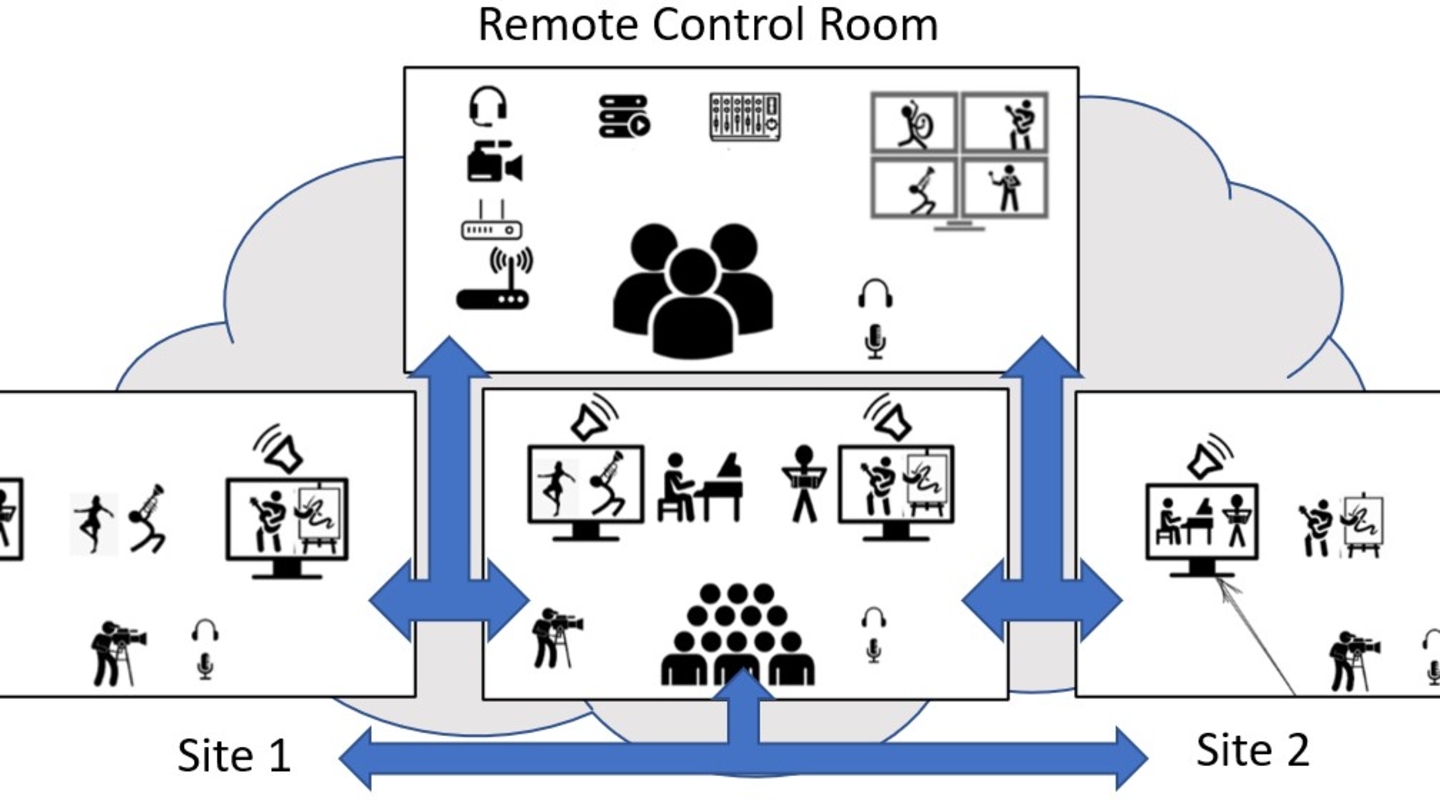
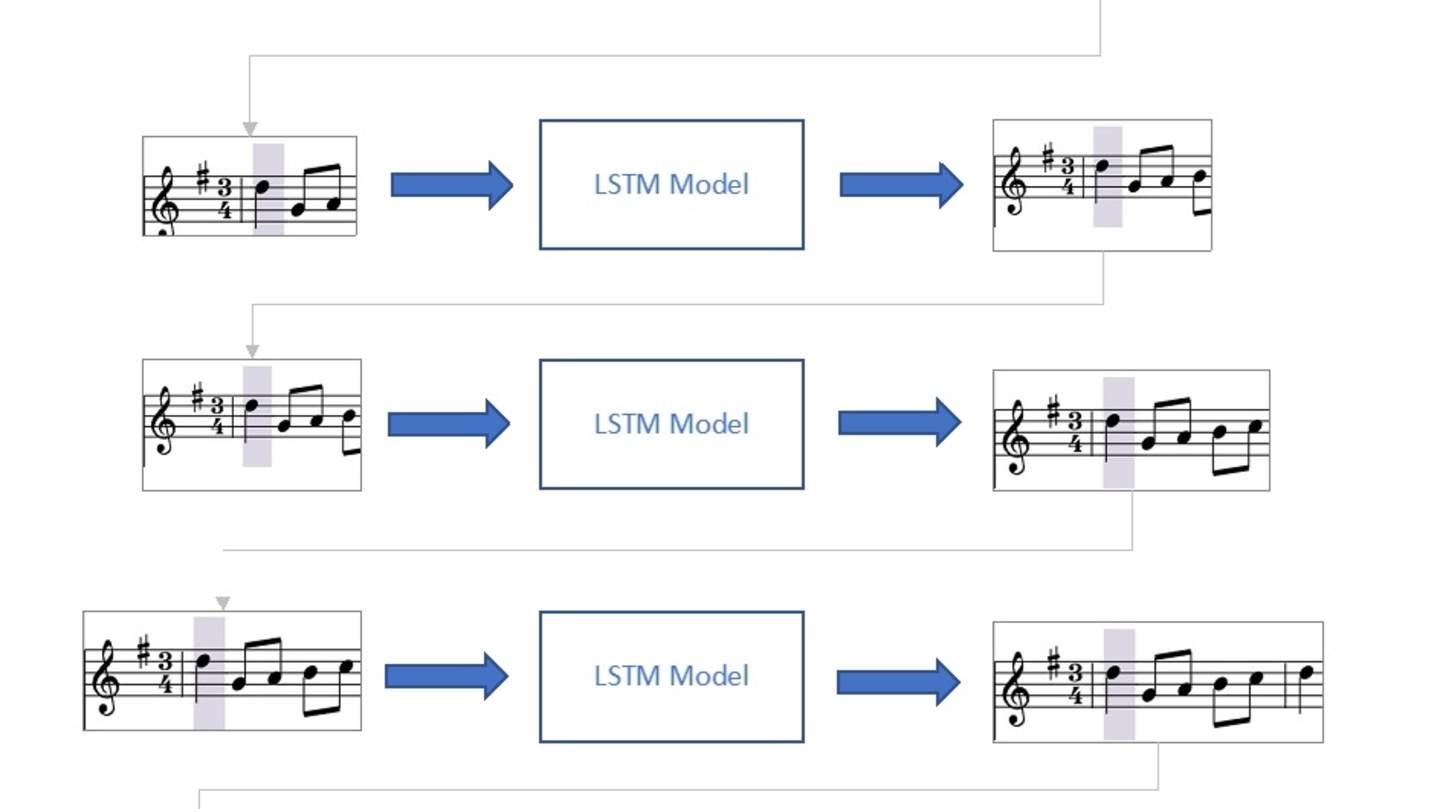
Efficient Delivery and Rendering on Client Devices via MPEG-I Standards for Emerging Volumetric Video Experiences
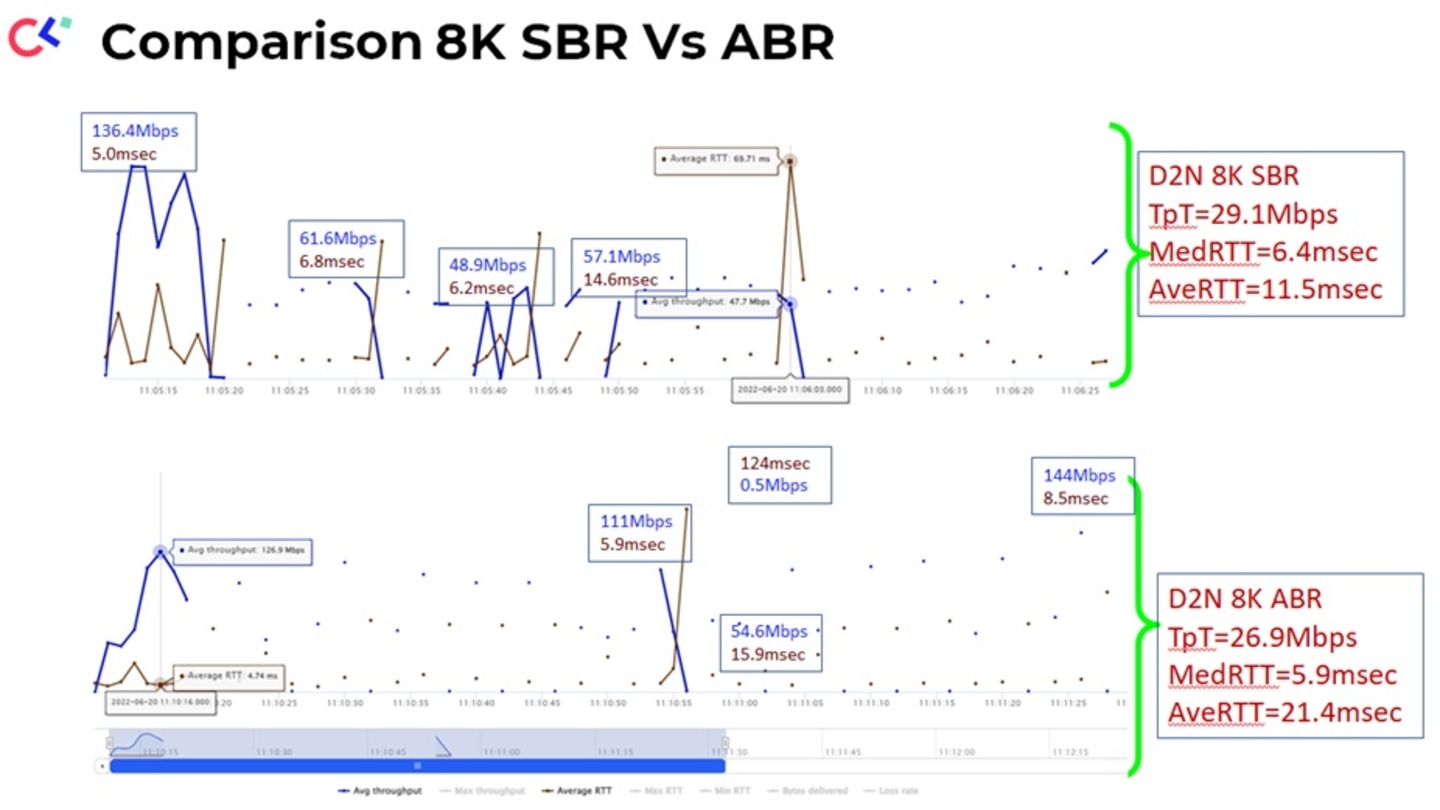

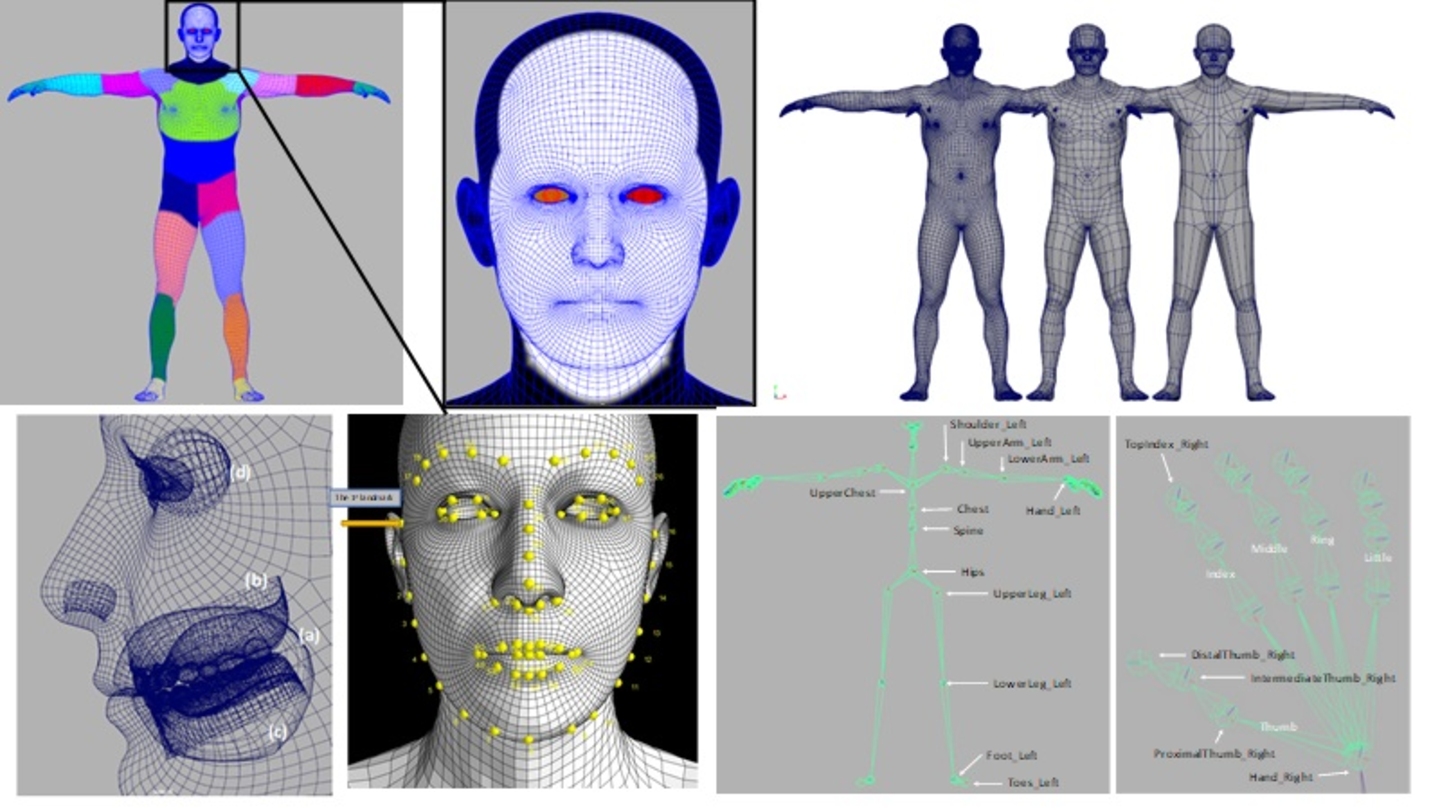



Reports
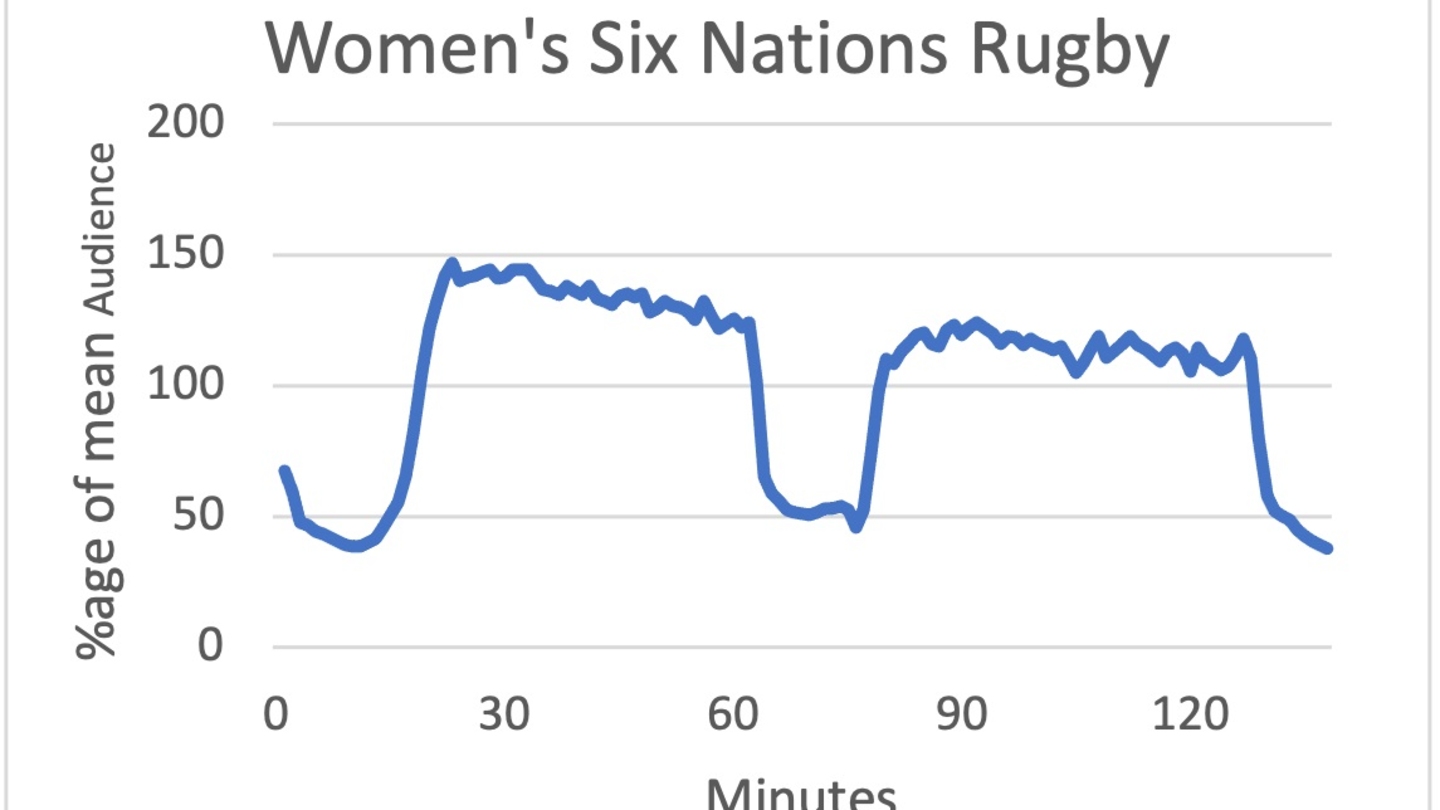
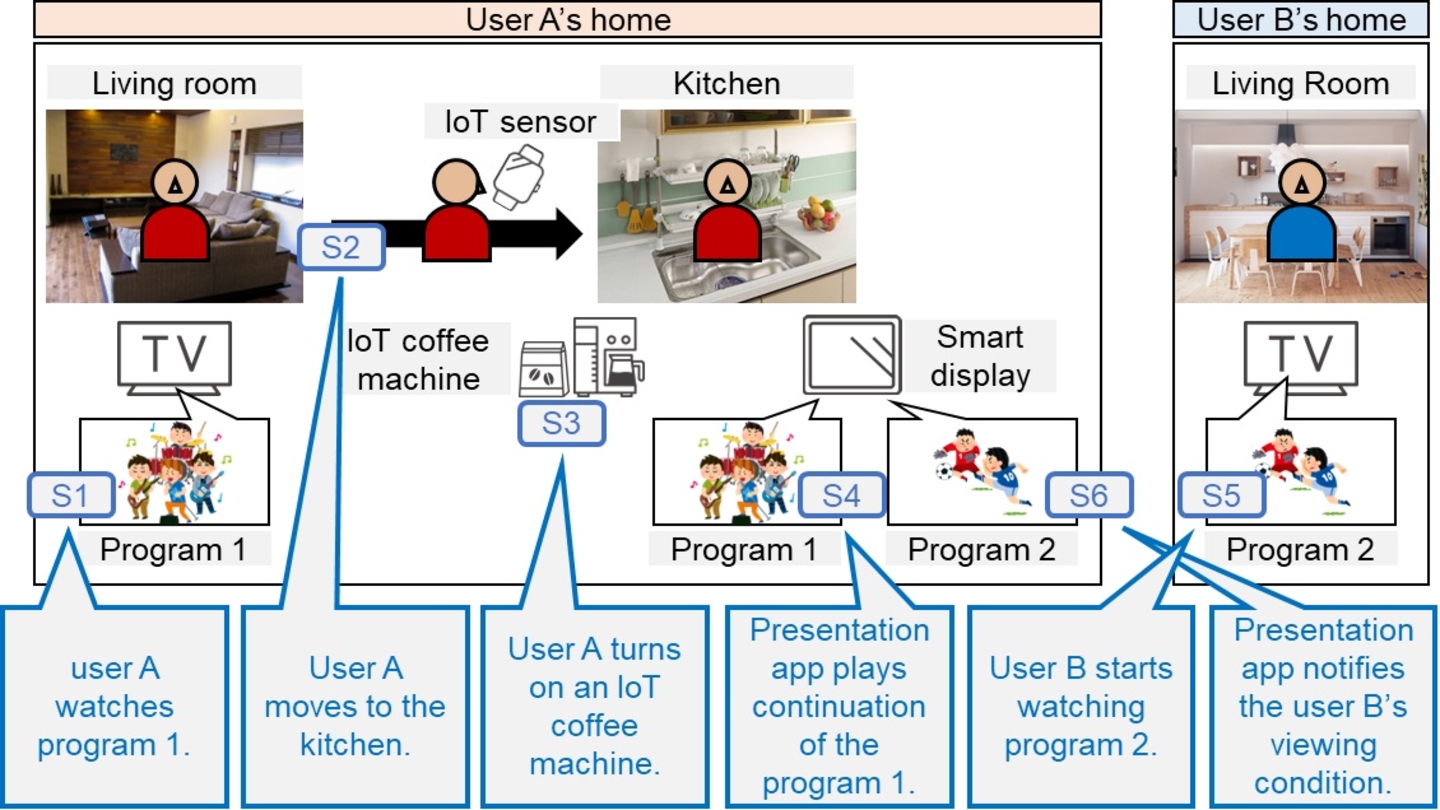
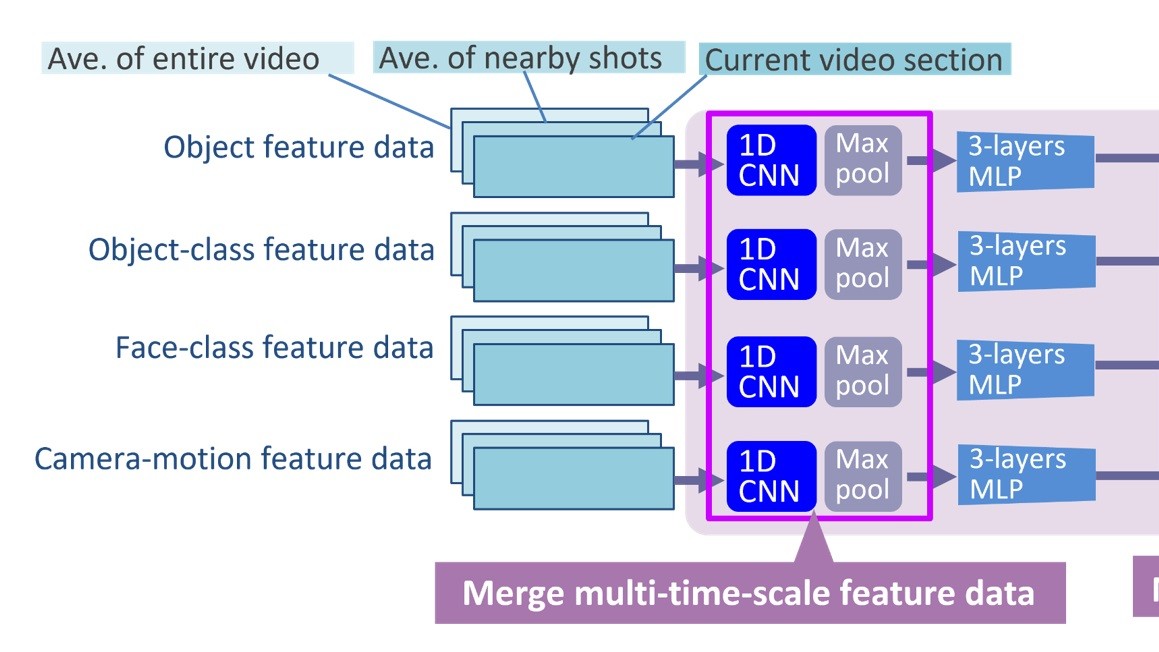
Recommendations For Improving On-Demand Content, Post-Broadcast Derived From An Analysis Of Minute By Minute Consumption Patterns
Reports
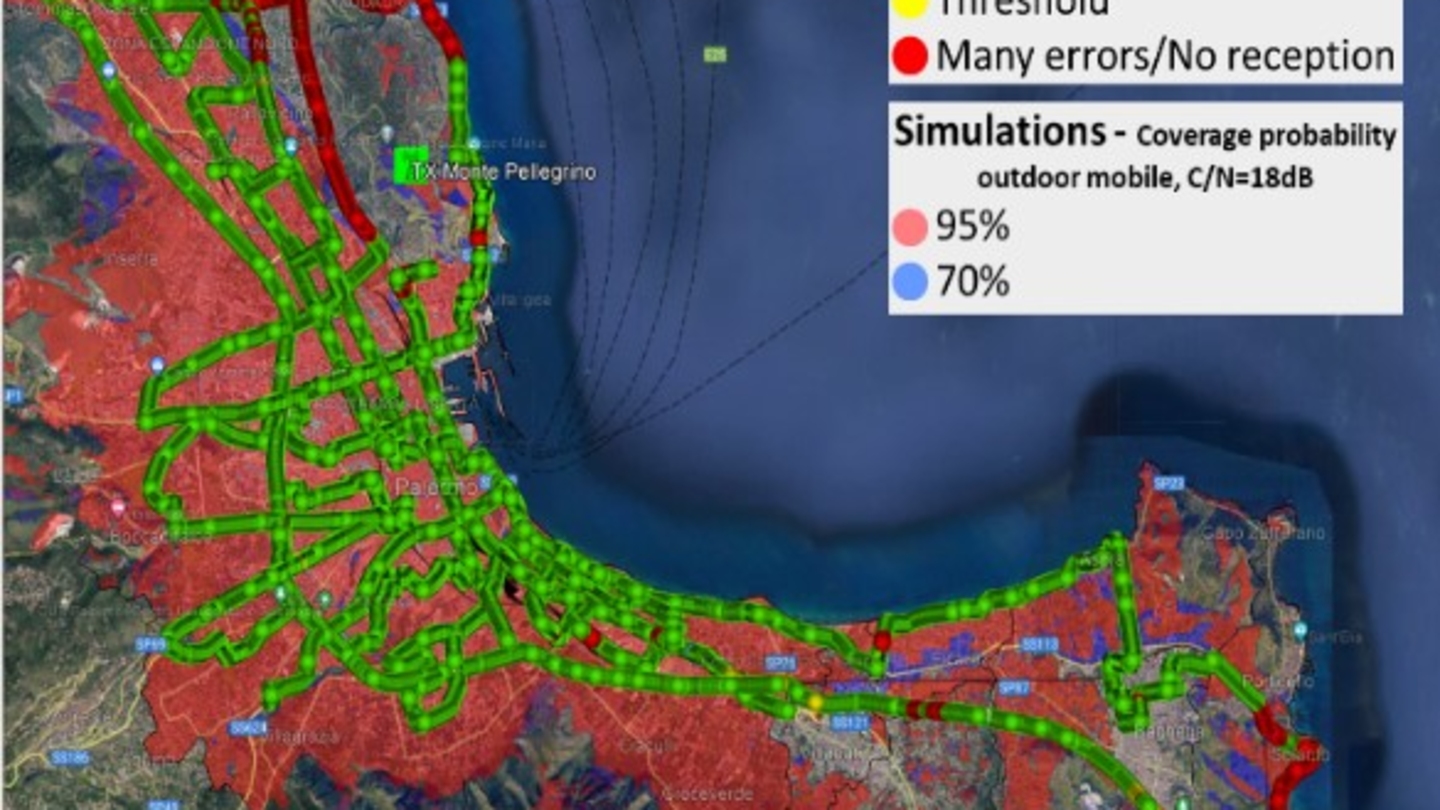
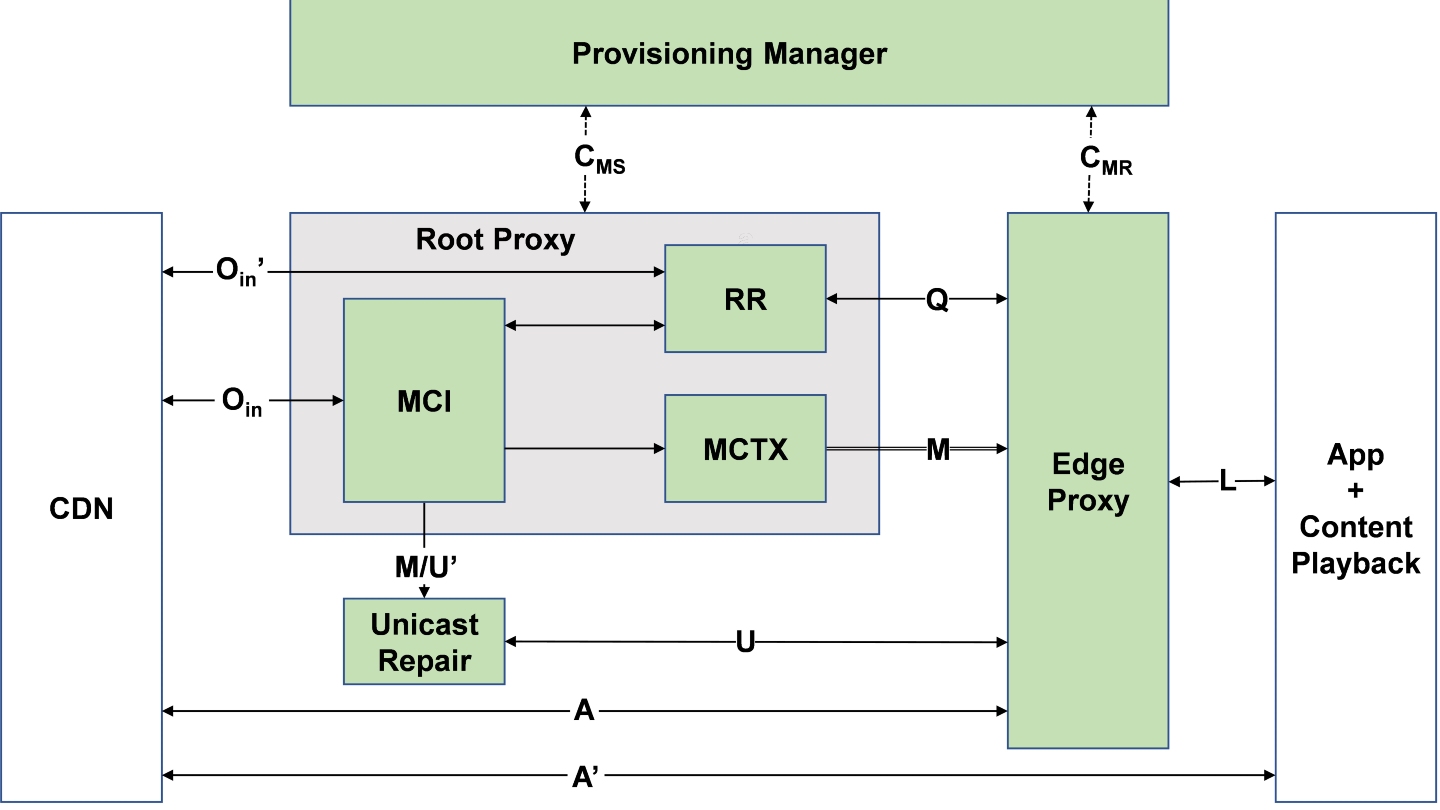
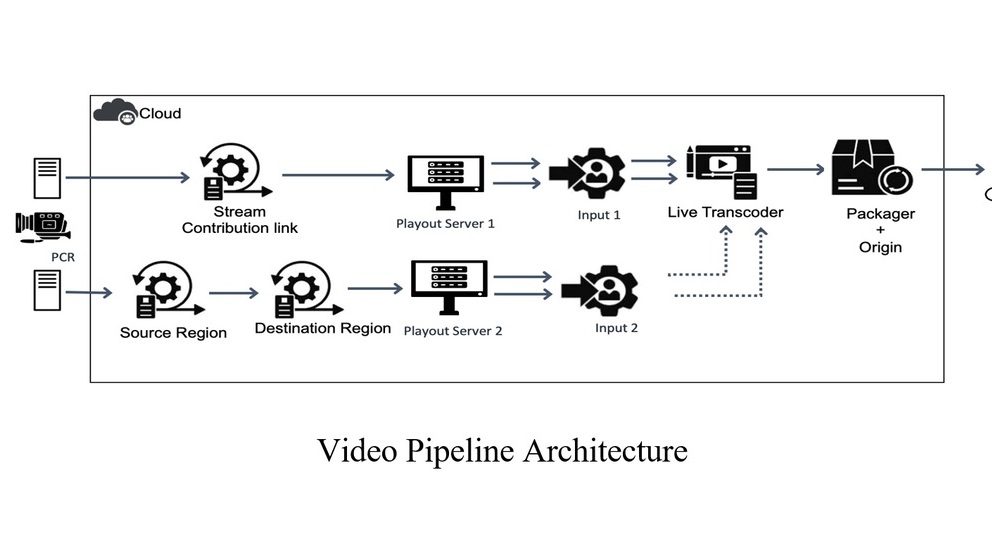
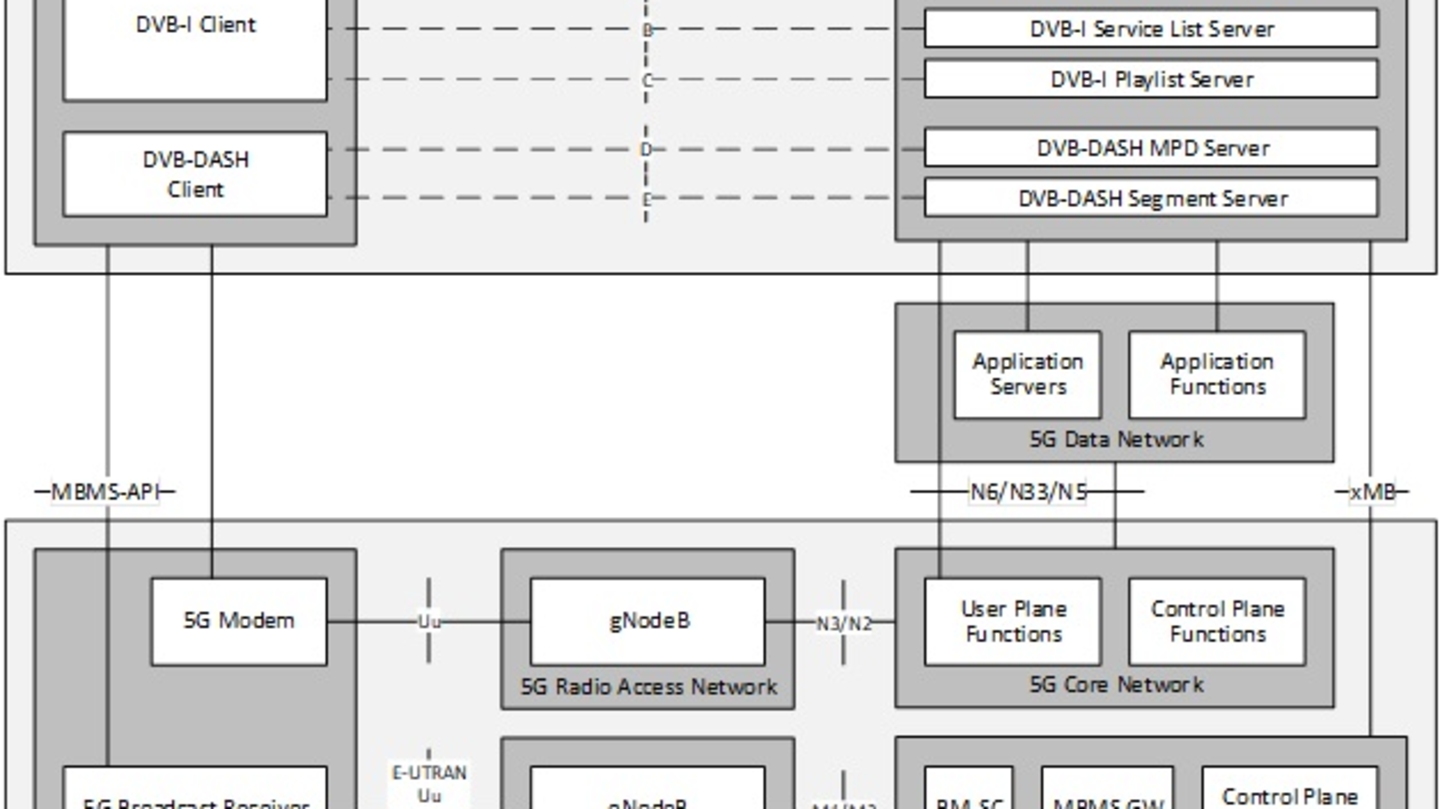
Efficient Delivery of Audiovisual Content to Mobile Devices Combining 5G Broadcast and CDN Technologies
Reports