Home
Watch
IBC2026
IBC Daily
Log in
Enter keywords
Submit search
Watch
IBC2026
IBC Daily
Accelerating Innovation
Accelerating Innovation
IBC Accelerators
Tech Papers Hub
Intellectual property
Artificial Intelligence
Artificial Intelligence
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
Connective Tech
Connective Tech
5G
6G
Cloud
Digital Audio Workstation
Edge Computing
IP Workflows
Network Slicing
IBC Show
IBC Show
IBC2024
IBC2023
IBC2025
Immersive Tech
Immersive Tech
AR
Immersive Audio
Metaverse
MR
Spatial Computing
Volumetric Video
VR
XR
OTT & Streaming
OTT & Streaming
AVOD
CDNs
FAST
SVOD
TVOD
People & Purpose
People & Purpose
Acquisition & Retention
Diversity, equity & inclusion
Skills & Training
Sustainability
Production
Production
Audio Tech
Camera Tech
Content Acquisition
IP Production
LED Volumes
Live Production
Outside Broadcast (OB)
Remote Production
Sports Production
Storytelling
Studio Production
Virtual Production
Virtual Production
Camera Tracking
Worldbuilding
Motion Capture & Performance
Rendering & Compositing
Robotic Cameras
Enter keywords
Submit search
Content Management
Metadata
Topics:
Archiving & Storage
Codecs & Compressions
Content Transcoding
Media Asset Management
Media Transport
Metadata
Playout
Systems Integration
Testing & Measurement
Blockchain
Choose a topic
Archiving & Storage
Codecs & Compressions
Content Transcoding
Media Asset Management
Media Transport
Metadata
Playout
Systems Integration
Testing & Measurement
Blockchain
View other themes:
CHOOSE THEME
ACCELERATING INNOVATION
ARTIFICIAL INTELLIGENCE
CONNECTIVE TECH
IBC SHOW
IMMERSIVE TECH
OTT & STREAMING
PEOPLE & PURPOSE
PRODUCTION
VIRTUAL PRODUCTION
Features
Crafting suspense: “We wanted to raise the bar again”
Read now
Features
IBC Content Everywhere: Personalisation and the role of AI
News
Big Blue Marble partners AWS European Sovereign Cloud
News
Bitmovin appoints Co-CEO
Features
Content Everywhere: A look back at 2025
News
ThinkAnalytics appoints Senior Vice President of Advertising
News
Bitmovin ties with ThinkAnalytics
News
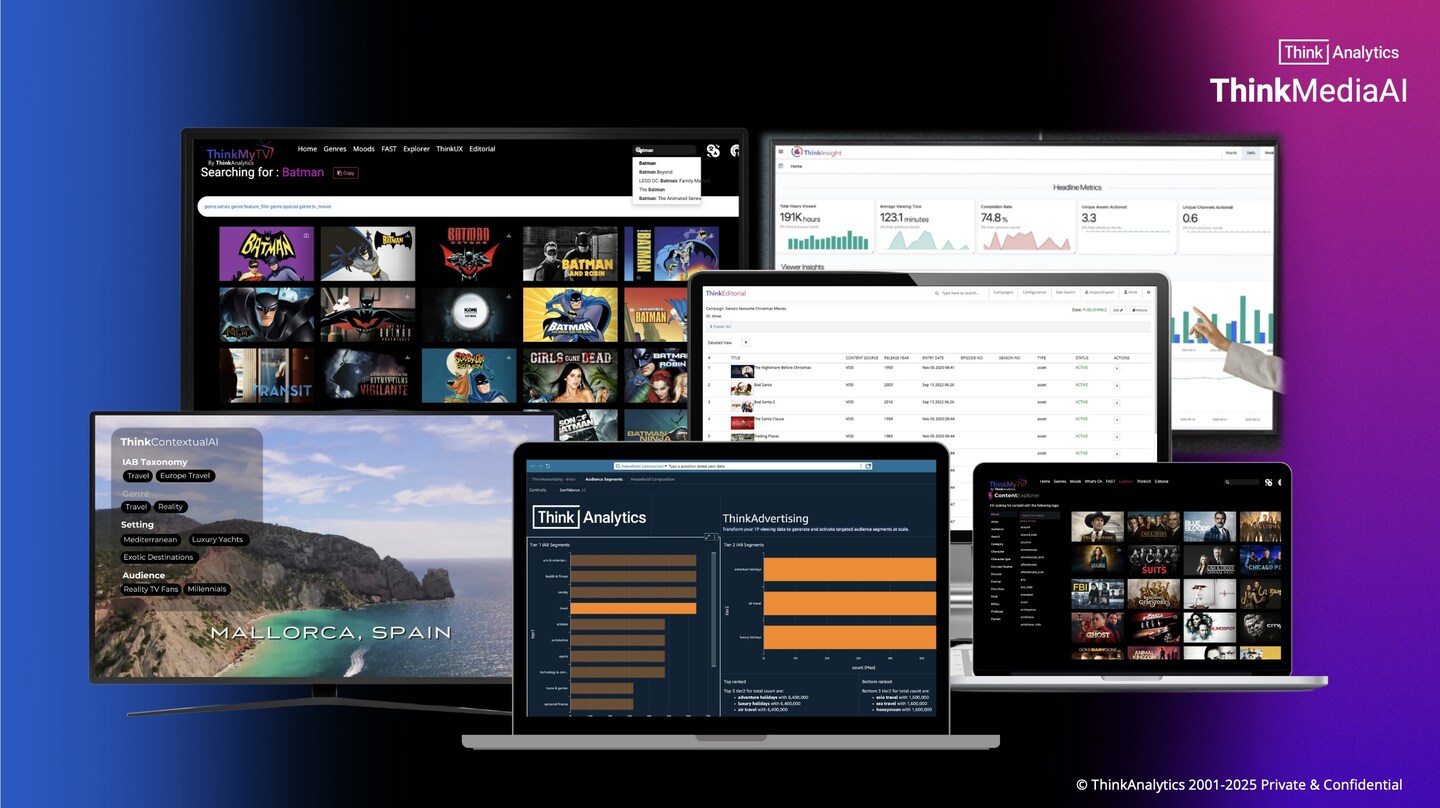
ThinkAnalytics launches agentic AI metadata
Features
From pilots to production: GenAI and DAM combine for scalable workflows
Features
ABC Assist: Harnessing AI to empower journalists, not replace them
Features
CTO Roundtable: WBD and ITV chart the future of AI in media
Features
How DAZN used data to tame multiple CDN’s for the FIFA Club World Cup
Interview
Future Tech: Framedrop brings a streamlined publishing workflow to IBC2025
Interview
Future Tech: Magnifi to launch AI-driven sports broadcasting solution at IBC2025
Interview
Future Tech: Collabora showcases AI-driven open-source tools for the media industry at IBC2025
Interview
Future Tech: Dot Group to launch sustainability tracker for broadcaster IT operations
Interview
Future Tech: Southworks showcases AI-powered video content management at IBC2025
Interview
Future Tech: Media Press Group presents the future of contextual metadata
More