Home
Watch
IBC2026
IBC Daily
Log in
Enter keywords
Submit search
Watch
IBC2026
IBC Daily
Accelerating Innovation
Accelerating Innovation
IBC Accelerators
Tech Papers Hub
Intellectual property
Artificial Intelligence
Artificial Intelligence
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
Connective Tech
Connective Tech
5G
6G
Cloud
Digital Audio Workstation
Edge Computing
IP Workflows
Network Slicing
IBC Show
IBC Show
IBC2024
IBC2023
IBC2025
Immersive Tech
Immersive Tech
AR
Immersive Audio
Metaverse
MR
Spatial Computing
Volumetric Video
VR
XR
OTT & Streaming
OTT & Streaming
AVOD
CDNs
FAST
SVOD
TVOD
People & Purpose
People & Purpose
Acquisition & Retention
Diversity, equity & inclusion
Skills & Training
Sustainability
Production
Production
Audio Tech
Camera Tech
Content Acquisition
IP Production
LED Volumes
Live Production
Outside Broadcast (OB)
Remote Production
Sports Production
Storytelling
Studio Production
Virtual Production
Virtual Production
Camera Tracking
Worldbuilding
Motion Capture & Performance
Rendering & Compositing
Robotic Cameras
Enter keywords
Submit search
Production
IP Production
Topics:
Audio Tech
Camera Tech
Content Acquisition
IP Production
LED Volumes
Live Production
Outside Broadcast (OB)
Remote Production
Sports Production
Storytelling
Studio Production
Choose a topic
Audio Tech
Camera Tech
Content Acquisition
IP Production
LED Volumes
Live Production
Outside Broadcast (OB)
Remote Production
Sports Production
Storytelling
Studio Production
View other themes:
CHOOSE THEME
ACCELERATING INNOVATION
ARTIFICIAL INTELLIGENCE
CONNECTIVE TECH
IBC SHOW
IMMERSIVE TECH
OTT & STREAMING
PEOPLE & PURPOSE
VIRTUAL PRODUCTION
News
Bangkok to host first-ever Eurovision Song Contest Asia in 2026
Read now
News
Canal+ wins key piracy case in French courts
News
Black Mirror to come to life in immersive experience
News
Europe’s audiovisual market is worth €142bn – report
News
Disney kills $1bn OpenAI deal after Sora shut down
News
2026 Bafta TV nominations dominated by Netflix's Adolescence
News
Adolescence picks up four RTS Programme Awards
News
Prime Video unveils huge slate of India originals
News
Dana Walden unveils leaders of expanded Disney Entertainment
News
BBC calls for Donald Trump’s $10bn defamation claim to be thrown out
News
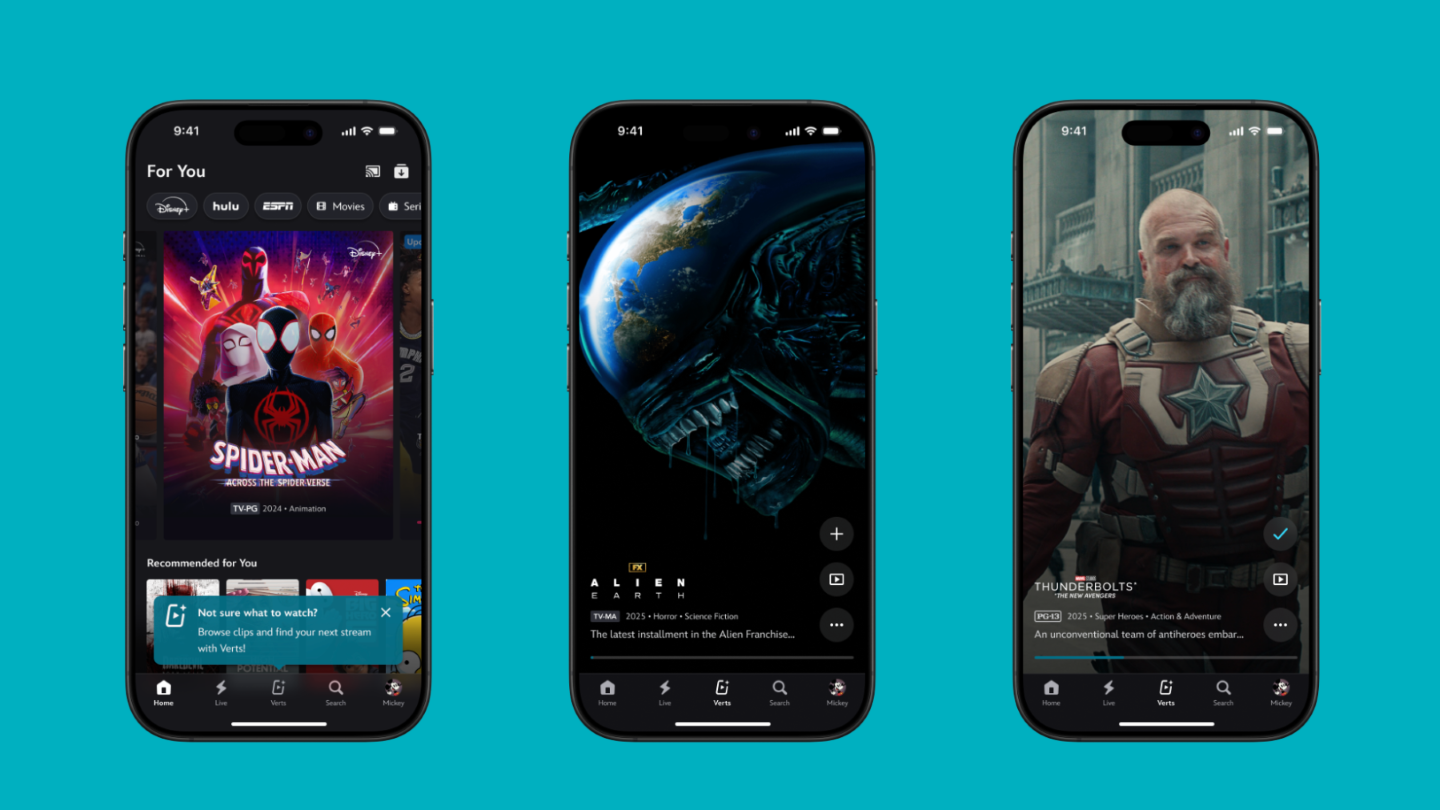
Disney+ launches vertical video feed Verts
News
One Battle After Another wins six Oscars
News
Netflix opens visual effects studio in India
News
Fifth Season acquires UK producer Story Collective
News
Tim Davie on “national asset” BBC World Service: “We should be doubling the funding”
News
Documentary Film Council appoints Mandy Chang as CEO
News
Michael Bauman wins ASC Award for One Battle After Another
News
BBC garners 47 nominations for Royal Television Society Programme Awards 2026
More






.JPG)




.jpeg)
.jpg)

.jpg)
